Claude Code 80%的提示词说删就删:Anthropic用Fable 5打了个样:AI行业的降本才刚刚开始
Anthropic在算力上的开销已达薪资支出的2.3倍,每位工程师年耗约51.5万美元,凸显“人不如模型贵”的现状,并引出AI成本失控的深层问题。
在这种巨额账单的压力下,连Claude自身也不得不开始精打细算token的使用。
Claude Code:烧 token 换“我很高产”的错觉
业界近期涌现了一个新词汇:Token Apocalypse(Token末日)。
从token maxing到token apocalypse,这预示着AI行业正经历一场巨大的范式转变。今年三四月间,大家还在比拼token消耗量,甚至将其视为一种排行榜。但使用AI并不自动带来成本节约,于是人们开始更加关注单个token的实际成本。
更微妙的是,大模型还在不断扩展那些原本无需AI介入的工作领域。我们现在不愿自己阅读PDF或长文,所有内容都交由AI总结。或者用AI将这些材料转成幻灯片,再丢给他人,对方可能又用AI重新消化这些幻灯片……AI似乎为一些本就虚浮的工作强加了一层价值,同时也悄然推高了账单。
如今,成本失控已成常态。亚马逊、Adobe、Atlassian、花旗集团等企业开始对AI使用实施严格管控:
限制模型等级:部分公司员工被禁止使用Claude Opus等高端模型,被迫降级到更便宜的版本。
设定个人限额:Uber为每位工程师设定了每月1500美元的token上限。
彻底停用权限:花旗银行等机构已完全限制对高级AI工具的访问,未达到使用目标的员工甚至被撤销企业账户。此前,Uber的CTO曾坦言,公司在几个月内就用完了全年AI预算。Walmart最近也停止了一些工具的使用。
大公司要么四处寻找省钱方法,要么直接给token浪费踩急刹车。因此员工收到的信息矛盾重重:一边是“AI能让你效率翻100倍,必须使用”,另一边却是“别再把公司用破产了”。
这也是AI工具第一轮普及中最典型的问题:工具被推出时,缺乏足够的护栏来阻止企业在大语言模型上花费数百万美元,也没有机制提醒团队token正在迅速消耗。无论是聊天机器人还是编码工具,许多产品首先确保“能用起来”,而成本治理、使用配额、模型分级和上下文管理都被延后处理。
但Claude Code本质上并非效率工具,而是一个营销工具。
它的设计目标明确:让你感觉自己处于高产状态。Boris,Claude Code的项目负责人,在构思产品时最初的思考是:“如果模型变得足够聪明,代码会变成什么样?我希望如何使用这些东西?”——出发点不是“如何帮开发者省token”,而是“如何展示模型的聪明”。
Anthropic愿意为这种“感觉”烧掉大量token——无论是你的钱,还是它们自己的钱。五分钟花掉200美元,对Claude Code来说不是事故,而是设计。其底层逻辑是:能多烧token解决的问题,绝不寻找更省token的方法。所有sub-agent、所有花哨的UI动画、所有冗长的reasoning trace,都不是为了效率,而是为了让你盯着屏幕时,觉得“这模型真聪明,真能干”。
这背后是一个精心设计的营销闭环:你烧掉大量token,换来“高产”的感觉,于是觉得Claude好用,然后继续使用。Anthropic甚至愿意自己承担大量token成本,以换取这种情绪上的认同。这也是为何它们的桌面应用投入明显不足——Claude Code的目标从来不是做一个好工具,而是成为Anthropic模型能力的“最佳展示窗口”。
恰恰是这种“烧token换体验”的设计哲学,让Claude在token效率上被OpenAI甩开了。
OpenAI一直在拼命压缩token。从reasoning trace的压缩,到模型本身的效率优化,它们的哲学是:用更少的token,完成同样的任务。Codex 5.5就是最佳例证。
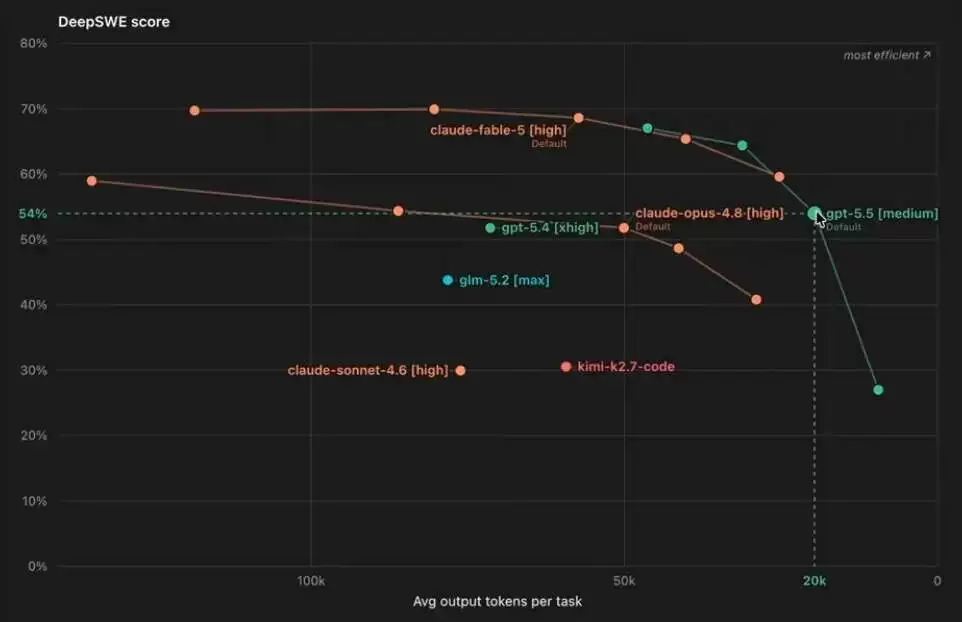
尽管像Fable 5这样的模型很智能,但与其他模型相比,它的效率并不算高,Deep SWE的这张图能说明问题。若将同批模型放在一起对比,则更明显:GPT-5.5 medium仅用了2万个token,就拿到了惊人分数;而Opus 4.8用了5万个token,得分反而更低。
这就是两条路线最直接的写照:行业在恐慌,Claude在消耗,OpenAI在节省。接下来的问题就是——既然要降本,第一个该砍的是什么?答案是:那些堆积了太久的提示词。
Claude Code 的 Prompt 债:堆得越多,欠得越多
在最近的演讲中,Anthropic表示,他们已经删除了Claude Code中80%的系统提示词。

Anthropic技术团队成员Tariq Shihipar解释说,这反映出AI模型引导方式正在发生根本变化——过去,人们认为指令越多、例子越多,模型表现就越好;但现在,这一逻辑不再成立。新模型Fable 5比它们自己提供的示例更具想象力,示例反而成了束缚。
这当然有营销成分,他吹嘘了一把Fable的能力:“示例反而容易限制模型,因为它实际上比我们给出的示例更有想象力”。但一个事实无法回避:连Anthropic自己都开始对system prompt下手了。

那么,为什么以前需要那么多prompt?
过去一两年,AI Coding圈形成了一套惯性思维:上下文越大越好,工具说明越多越好,system prompt越完整越好。模型不知道项目如何组织?写Agents.md。模型不知道工具怎么用?写tool descriptions。模型不够主动?写行为引导。模型不够稳定?继续往system prompt里加约束。
不可否认,system prompt曾经是AI Coding工具的核心竞争力。对LLM的prompt做一些小调整,就可能带来显著的性能提升。如果同一个模型在Codex、Cursor、OpenCode和Copilot里的感觉不一样,那几乎肯定是因为prompting上存在细微差异。
这也是为何Cursor曾花费大量时间测试system prompt,做A/B testing,针对不同模型微调提示方式。与在Claude Code中使用Opus相比,Cursor的harness能显著提升模型表现,一些benchmark测到的提升甚至高达10%到30%。差别核心往往就是那几段prompt。
但问题在于,只要prompt有用,团队就会不断往里添加内容。某个模型喜欢乱用工具,就加一段规则;某个模型不够主动,就加一段鼓励;某个模型搜索太多,就补一段限制;某个模型不理解项目上下文,就再加一个markdown文件。每一次增加都有理由,但长期堆下来,system prompt开始变成一个巨大的常驻上下文包袱。
问题在于:system prompt不是免费的。它每次调用都要被读入、计费、占用上下文。
Claude Code将所有工具和功能内置进去之后,system prompt一度膨胀到65,000个token;即便关闭大部分功能,也还有12,000个token。换句话说,模型还没开始写一行代码,就已经背上了一本说明书。对比来看,Pi启动时上下文不到一千个token。
更麻烦的是,prompt债比代码债更隐蔽。
代码老化后,通常会在改功能、跑测试、处理bug时暴露出来。Prompt老化后,却可能只是让模型悄悄变差。用户看到的是“Claude Code最近好像不如以前聪明了”,或者“新模型没有宣传得那么强”,但真实原因可能是旧的system prompt没有跟上新模型。
当prompt从竞争力变成负担时,Anthropic选择删除80%,并能进一步提升token效率。
Claude 的“废话税”:多说一个字,多花一份钱
Claude Code的废话实在太多。
今年有一个名为Caveman的插件迅速走红,专门解决这个问题。它的名字直译是“穴居人”,意思是像原始人一样说话——不讲礼貌,不加多余语法,不放填充词,只保留核心意思。
"Caveman save you token, save you money. Star cost zero."
乍一看,它听起来像个玩笑。但一旦理解,你会发现它解决的是LLM中一个非常真实的问题:废话太多、token太多、成本不必要地变高。
而它的起源,正是针对Claude Code。
“我是在4月初做出Caveman的,因为那段时间我重度使用Claude Code,并且注意到我的很多token花费都浪费在了不必要的文字上:寒暄、模糊措辞、过渡语,以及那些在agent loop里其实并不重要的闲聊式表达。”Caveman的创建者Julius Brussee说。
Brussee的评测显示,Caveman相比默认输出能减少65%到75%的输出token,效果仍然超过普通的“请简洁”指令。它主要压缩的是周围的语言,不影响代码、命令、路径、URL、函数名这些需要精确性的部分。
据报道,OpenAI的工程总监Shayne Sweeney也为该项目贡献了代码,以支持Codex。
更有意思的是,OpenAI早已将这种语言模式应用到思考环节。
一些泄露出来的reasoning trace(并非对外显示的reasoning summary)让外界看到了端倪。内容不像普通英语,更像压缩过的工程速记:
"Use core new nodes. Need infer. Need add VAE encode for images. Try. Try period."
这些句子看起来很好笑,甚至有些杂乱,但它们的重点不在可读性,而在token效率。模型在内部推理时,不需要像对用户说话那样保持礼貌、完整和流畅。它只需要保留动作、对象、判断和下一步。换句话说,只要最终答案是正常的,模型内部完全可以用一种更短、更粗糙、更省token的语言完成思考,以疯狂追求token效率。
这甚至比在写Prompt环节更有用。压缩reasoning token的收益更大,因为agent是多步执行的,前一步的思考会变成后一步的输入。模型每少“想”一段,省下来的就不只是当下这几个token,而是后面整条执行链上的重复开销。
这正是OpenAI和Claude路线上的一个明显差异。
Claude一直更好聊,也更像一个用完整语言思考和表达的助手。只要看看它的reasoning trace长很多,就能猜到它可能是在用普通英语。它的输出和reasoning往往更长,所以更依赖大上下文窗口来容纳这些内容。
这也是为什么Claude默认使用100万token的上下文窗口。很多人以为这是因为它想装进更大的代码库,但原因其实更简单:Claude生成的东西太长了,没有这么大的窗口装不下。它们在compaction上也很差,当你恢复旧线程时,Claude会建议你不要保留完整上下文,而是尝试compact。因为它们不会保留reasoning trace——事实上,它们会在10到20分钟后清掉这些东西,因为reasoning token效率太低,不值得一直保留,否则成本会荒谬到不可接受。
而OpenAI模型的token上下文窗口大概是20万或更少,但因为它们从一开始就通过这种简短语言做到了压缩。
如果Anthropic能够解决输出内容冗余的问题,其收入将面临下滑,因为更少的token意味着更低的收费,这暴露出token效率与商业利益之间的内在矛盾。