专访大晓李鸿升:一脑多型背后ACE-Ego开辟具身规模化训练新路径
2026年年中已至,具身智能领域的热度依旧未见消退。融资动态、模型发布、行业峰会与技术演示接连不断,整个赛道的叙事也从“具身智能元年”悄然切换至“商业化落地关键年”,一轮又一轮的概念翻新推动着市场前行。
然而,在喧嚣表象之下,一个更为根本的难题正逐渐浮出水面:支撑具身模型持续迭代的高质量训练数据,正变得日益稀缺。行业中普遍采用的真机遥操作采集方式,受限于成本、场景覆盖以及机型多样性,已逼近数据多样性的天花板。
如果标准化的示教方式无法教会机器人应对真实世界中的复杂变量,那么具身模型下一阶段的训练养分又该从何处汲取?
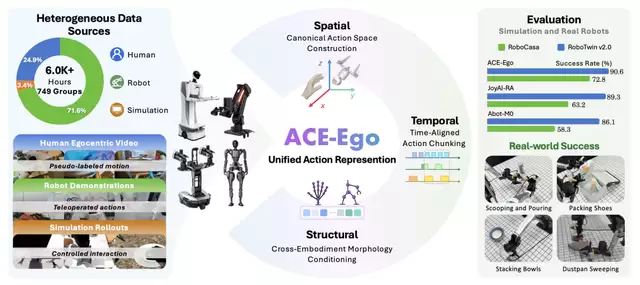
针对这一困局,大晓机器人正式发布并开源了全新的“一脑多型”具身操作VLA模型——ACE-Ego。该模型将大规模第一视角人类视频与多机型机器人数据进行联合预训练,将人类与物理世界交互的经验,转化为机器人可学习、可迁移的监督信号。
在国际人形机器人操作基准RoboCasa GR1 TableTop上,ACE-Ego以72.8%的平均成功率刷新了当前最高纪录;而在高难度双臂操作基准RoboTwin 2.0强域随机化测试中,ACE-Ego更是取得了90.62%的成功率,展现出卓越的环境鲁棒性。
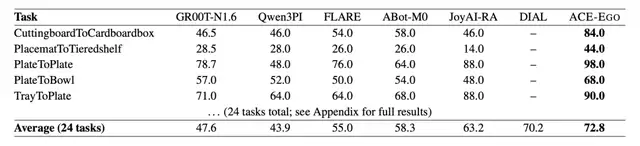
更为关键的是,在引入第一视角人类视频进行联合预训练后,ACE-Ego在RoboCasa上的成功率从68.3%提升至72.8%。这表明,“借人之眼”并非仅是简单扩充数据量,而是为具身模型开辟了一条更低成本、更高泛化能力的规模化训练路径。
目前,ACE-Ego已能够稳定完成塑料袋打包、鞋子装入鞋盒等长周期、强接触的复杂零售操作。这些操作覆盖了商品整理、打包履约等典型的线下零售环节,突破了以往模型大多停留在简单桌面抓取的能力边界。

(大晓机器人世界模型科学家李鸿升)
近日,我们与李鸿升进行了深度对话。在他看来,ACE-Ego的意义远不止于一次SOTA成绩的刷新,更是“以人为中心”的ACE研发范式在具身模型预训练中的关键落地:从遥控机器人采集数据,转向借助人类第一视角理解真实世界;从单一本体训练,走向多机型协同预训练;从实验室任务,迈向可规模化落地的产业场景。

在相当长的一段时间里,遥控操作采集被业界视为黄金标准。通过建设专门的素材厂,配置专业的遥控人员,让机器人在真实本体上一丝不苟地完成每一个动作,并将每一帧轨迹精确记录下来,以此作为模型学习的训练数据。这套方法论严谨、可控且精准,被大多数机器人团队奉为圭臬。然而,近两年来越来越多的人意识到,这种标准化操作正逐渐成为制约机器人发展的天花板。
首当其冲的是成本压力。从场地租赁、硬件集成到专业遥控人员的配置,前期投入动辄数百万元。作为一项劳动密集型工作,一名熟练的遥控人员一天内能够采集的有效数据时长非常有限。
成本问题或许还能通过融资来解决,但技术层面的限制则更为根本。一个素材厂一旦搭建完成,其场景、光照、物体位置、工作台的高度和材质便基本固定。机器人学到的所有动作,都被绑定在这套固定的物理配置之上。
李鸿升对此感受颇深:“数据多样性的上限很低,除非你将整个素材厂搬迁并更换布景,否则模型就被困在那个固定环境里了。”
这也就是行业常说的泛化能力不足。真实世界的变量远超素材厂所能模拟的范围,机器人无法做到举一反三。在素材厂里接受训练的模型,就像从小到大只做过标准试卷的学生,一旦考题稍微换个问法便会手足无措。仿真数据试图以更低的成本解决这一问题,但sim-to-real的鸿沟至今仍未被完美跨越。
转向人类第一视角视频以获取现实世界的真实数据,正是对这个困局的回应。“借眼入局”不仅绕开了高昂的采集成本和技术瓶颈,更摆脱了那条越走越窄的标准化答案之路。
但“借来”的眼睛所看到的东西,距离机器能够理解的语言,却还有很长一段距离。

眼睛看到了,并不等于机器真的理解了。对于人类如此,对于机器更是如此。
人类日常操作视频最大的价值在于其真实性和多样性。不同的人、不同的场景、不同的操作习惯,恰恰是实验室数据中最稀缺的真实世界养分。然而,非结构化、缺乏统一标准、差异极大的真实世界数据,就像一本用不同方言写就的无字天书。未经处理的数据直接输入模型,不仅无法成为养料,反而会扰乱已有的认知体系。
李鸿升认为,要将第一视角人类视频转化为机器能够理解的信息,需要跨越四道门槛。
第一是空间坐标系不对齐。1.8米和1.5米身高的人,其胸前相机拍到的桌面角度完全不同,这种差异会使模型将本质相同的操作判定为完全不同的任务。
第二是本体构型不匹配。人类的指尖捏取动作对应到双爪机器人上则是夹爪闭合,两者的物理形态完全不同。如果无法在构型层面实现对齐,机器就读不懂人类动作的本质。
第三是时间帧率不一致。真人视频多按固定帧率采集,而机器人的动作控制拥有独立的响应频率,两套时钟的基准完全不同。在多源数据混合时,同样的一个伸手抓取动作,在真人视频里可能只有10帧,在真机数据里却是30帧。若按固定帧数切分,就会打乱动作的因果顺序与节奏,导致模型对动作的时间逻辑产生混乱。
第四是标签质量有误差。从视频反推得出的动作信息充满误差,手指末端以及被遮挡部分的“伪标签”,其精度远不及遥控数据的水平。
这四道门槛共同筑成了人机之间的认知鸿沟,也解释了为何许多团队明知人类数据成本低、多样性高,却不敢大规模使用的原因。
(ACE-Ego概览图)
“如果你只是简单地将人类视频和机器人数据混在一起训练,模型性能反而会下降,不会提升。”
人之眼看到的东西固然足够丰富,但唯有当它被准确转译为机器能够读懂的语言时,这种丰富性才真正具有价值。为了解决这些问题,大晓机器人团队针对每一个“不对齐”设计了相应的翻译机制。
空间上,统一第一视角坐标系。放弃以机器人本体为基准的传统思路,将所有真人视频、真机数据全部对齐到统一的第一人称视觉空间,通过几何校正抹平身高、机位、俯仰角所带来的视觉差异。只有让模型站在同一个视角看世界,动作的相对位置与空间逻辑才能被统一识别。
本体上,用URDF编码构建身份体系。依托机器人行业通用的URDF构型文件,团队设计了一套可学习的编码器,为每一款机器人的躯体构型都生成专属的表征编码,同时为人类肢体分配一套共享编码。
时间上,按物理时长替代固定帧数切分。不再使用固定帧数来划分数据片段,转而以真实物理时间为基准对齐所有数据源。无论视频帧率是多少、机器人控制频率有多高,都按统一的时间窗口进行切割,从而保证伸手、抓取、抬起等动作的因果序列与节奏不被打乱,让多源数据在时间维度上实现同频。
标签上,用动态置信度过滤噪声。针对伪标签的误差问题,团队为不同关节、不同遮挡情况设置了分层权重:对于手腕根部等重建精度高的部位赋予高权重,而对于指尖末端等误差大的部位则降低权重;短时间遮挡轻微降权,长时间遮挡大幅降权,从损失函数层面弱化噪声数据的干扰,使模型优先学习高可信度的动作信号。
这套转译体系的效果最终直接体现在了榜单成绩上。在RoboCasa GR1 TableTop排行榜上,ACE-Ego以72.8%的成功率刷新了当前最高纪录并夺得榜首;在RoboTwin 2.0强域随机化测试中,ACE-Ego以90.62%的成功率展现了远超行业平均水平的环境鲁棒性。

这意味着,翻译得越准确,“借人之眼”才越有可能铸就“机器之魂”。当模型见识过足够多样的人类行为和环境变化时,它对单一场景的过拟合现象便会自然得到稀释。
而当机器的灵魂初步成形之后,它面临的下一个问题则更为棘手:市面上的具身智能产品型号繁多,这颗通用的机器之魂,如何才能栖居进形态各异的机械躯体之中?

一套翻译方案成功跑通,意味着模型终于能够理解人类在做什么了。然而,理解是一回事,运用自身的身体将其实现又是另一回事。
人类用手捏起一个杯子,手腕旋转30度,手指自然调节力度……这一连串动作对于人来说是本能反应。但对于一个双爪机器人而言,双爪机械手需要计算开合的最大幅度以及夹持的力矩阈值;吸盘式末端则需要规划吸附的中心点以及抬起的垂直角度;即便是同一款灵巧手,臂长的差异也会导致到达同一位置的关节轨迹天差地别。
同一个“抓取打包”的认知目标,落到不同的物理躯体上,其执行路径、发力方式以及动作时序可能截然不同。这便是“魂”与“躯”的核心矛盾:认知内核可以是统一的,但每一副躯体都拥有自己独特的物理边界与运动规则。
行业内的主流解法始终未能跳出“一机一魂”的闭环逻辑。英伟达等玩家在布局VLA模型时,大多绑定自有硬件生态,深度适配自家机器人的构型参数与运动学模型。这些模型往往只为单一机型量身打造,更换一款臂长不同的同品牌机型都需要重新调整参数,更不用说跨品牌、跨构型的迁移了。
这种模式带来了几个后果。
一方面,研发成本重复投入。每一款新硬件上市,都要配套走一遍数据采集、模型训练、调试验证的完整流程,大量资源消耗在高度同质化的工作中;另一方面,模型能力被硬件出货量所绑定,单款机型的数据体量天花板直接锁死了对应模型的能力上限。高昂的适配成本使得大量中小企业望而却步,只能站在具身智能的浪潮之外观望。
(ACE-Ego技术架构图)
大晓机器人从一开始便跳出了“为特定硬件定制模型”的路径依赖,提出了“一脑多型”的设想。
在李鸿升看来,真正有生命力的机器模型,不应该被单一硬件的躯壳所束缚。
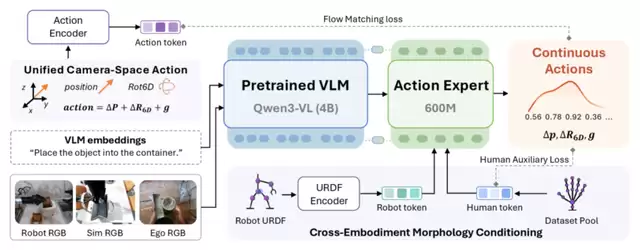
团队找到的破局密钥,隐藏在前文提及的URDF构型文件之中。他们设计了一套可学习的URDF编码器:每一款机器人的连杆长度、关节限位、力矩范围、自由度数量等所有物理参数,都能通过编码器映射到统一的语义表征空间。与此同时,人类肢体的结构也被赋予了一套共享编码,与机器人表征处在同一个特征体系之下。
打个比方,这相当于给“机器之魂”配备了一本通用的“躯体说明书翻译器”。无论是什么品牌、什么构型的机械臂,只要传入它的URDF文件,这颗“魂”就能快速读懂这具身体的能力边界,并将统一的认知目标拆解成适配当前躯体的动作序列。
在预训练阶段,团队便融合了星海图、智源、银河通用三款不同构型的真机数据,使“机器之魂”在训练阶段就接触过不同的躯体形态,早早学会了根据身体条件调整动作逻辑。到了下游适配环节,面对从未见过的方周双臂平台,模型也能依靠URDF编码机制快速完成迁移验证。
李鸿升透露,方案落地后,简单任务仅需50至100条人类演示数据,1至2小时即可完成新机型适配,极简场景下半小时便可上线。对比传统数周级别的适配周期,效率提升了一个量级。
大晓机器人从模型训练起家,早期并无自有机器人本体。这份“无硬件包袱”的出身,反而让团队天然站在了开放兼容的视角上。李鸿升始终认为,“机器之魂”的强大,从来不依靠绑定某一款硬件。恰恰相反,接入的躯体越多、吸收的数据越多元,智能内核的泛化能力才会越强,最终形成“数据越多、魂越强、适配越快”的正向循环。
这份开放的思路,也直接落地成了ACE-Ego的完整开源计划。
“我们不仅开放Checkpoint,还要同步开源真机任务数据集和完整训练脚本,让中小企业、学术团队拿到就能用,能够快速进行下游迁移。”
在他看来,具身智能还处于行业早期,没有哪家企业能够独自跑完整个赛道。开源是降低行业门槛、加速整体落地的必经之路,也是让“机器之魂”ACE-Ego惠及更多场景的方式,从而降低具身操作模型的训练与迁移门槛。

技术的价值,最终要落在真实场景之中。技术路径已经跑通,模型能力也已得到验证,那么哪一个场景能够快速解锁ACE-Ego的价值呢?
过去一年里,不少项目在融资阶段讲出了漂亮的故事,但到了交付环节却拿不出可规模化部署的产品。从demo到product,中间隔着的是场景定义的清晰度。越早想清楚“给谁用、解决什么问题”,就越有机会在这场长跑中存活下来。
对于ACE-Ego的落地节奏,大晓机器人始终保持着十足的冷静。他们没有喊出全场景通用的口号,而是选择零售场景作为第一块试验田。
在李鸿升看来,这是商业与技术双重理性的选择。
“如果追求一个像人类智能那样的通用模型,时间跨度会很大。但如果聚焦在特定任务上,一两年内,我们能落地很多标杆应用。”
从市场维度来看,零售与前置仓赛道具有天然的落地优势。一方面,赛道整体体量足够大,分拣、打包、分装这类重复性岗位普遍面临用工成本高、人员流动率大的痛点,品牌方与运营商有强烈的自动化替代意愿,采购需求集中且明确;另一方面,对比家居机器人零散的C端采购,零售客户以集中式采购为主,单家企业就能支撑数十台乃至上百台的部署规模,商业化闭环的速度快得多,能够让“机器之魂”的价值快速得到验证,也能反哺模型持续迭代。
从技术维度来看,零售场景的任务边界清晰,恰好适配当前阶段的模型能力。拣货、打包、分装这类标准化操作,核心都围绕抓取、放置、操作的动作逻辑展开,任务范围可控,便于快速采集足量的人类演示数据,完成场景适配与能力验证。更重要的是,真实零售场景天然存在商品差异、包装变化、光线波动等变量,这些真实世界的“不标准”既能持续检验“机器之魂”的泛化能力,又不会像家居场景那样任务过于分散、环境过于复杂,是性价比极高的练兵场。
目前,ACE-Ego已能够稳定完成塑料袋打包、鞋盒封装、咖啡分装等典型零售作业。
谈及未来的柔性制造、工业场景,他坦言还需要补齐两块短板:一是依靠自研的轻重两套可穿戴采集设备,大规模扩充工业场景的人类操作数据,让机器的眼睛看到更多专业场景;二是将VLA模型与自研的世界动作模型WAM打通,补足精细化操作的能力,让机器的心智更加强大。
面对当下行业中关于快速落地与泡沫论的两极争议,李鸿升的态度始终平和务实。在他看来,两种观点本质上指向的是不同的目标:如果期待的是像人一样无所不能的通用具身智能,那么这条路注定漫长,短期内过度炒作确实容易催生泡沫;但如果将目光投向具体的产业场景,聚焦一个个边界清晰的真实任务,具身智能的落地速度远比大众想象中更快。
“具身智能有一万条赛道,每一条赛道做深了,受益面都很广。”
过去几年,具身智能的主流叙事始终围绕通用人形机器人展开。行业更习惯于先打磨出类人的物理躯体,再逐步为其赋予智能。大晓机器人则反其道而行之,选择先淬炼出一颗独立于硬件的通用机器之魂,再让这颗智能内核主动去适配形态各异的产业躯体。这种先塑魂、再附体的思路,正在打开一种全新的行业可能性:具身智能的发展路径不再局限于先造人、再赋智的单线程模式;算法的迭代可以脱离硬件进度的束缚,持续吸收人类真实操作经验以完成自我进化;大量中小企业无需从零搭建模型团队,接入这颗通用机器之魂便能快速赋予产品操作智能。在数据荒漠中,这是一条需要更多耐心、更多工程细节以及更多跨模态翻译的路径,但一旦走通,便能绕开标准答案的囚笼,真正让机器进入真实世界。