RAG 检索优化策略:从命中率到答案质量的工程打法全套
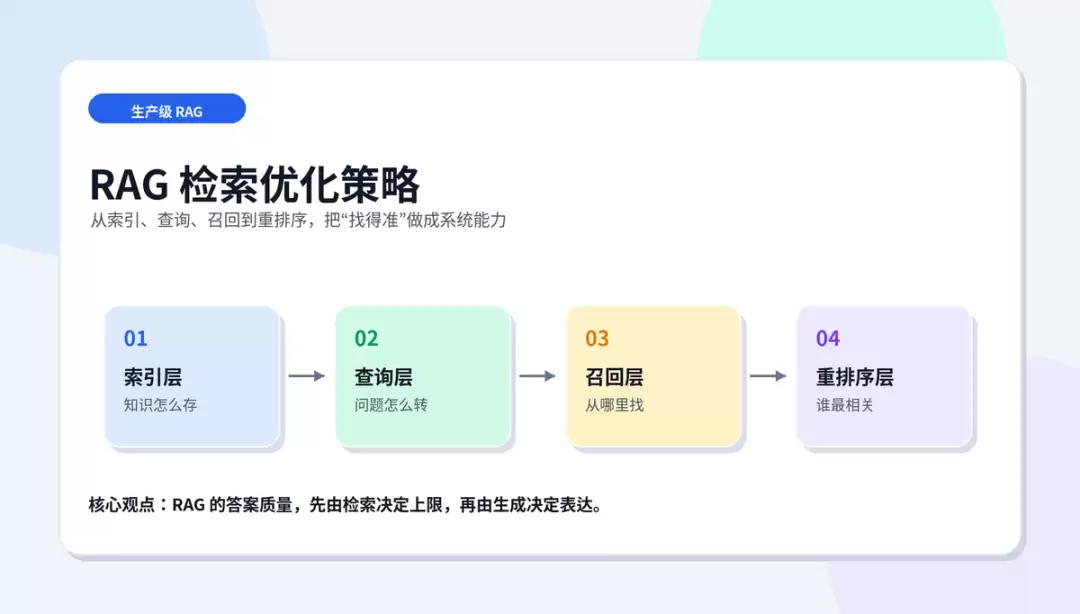
提升RAG系统答案质量的核心在于构建索引、查询、召回、重排四层优化体系,而非简单调整参数。
- 剖析生产级RAG常遇瓶颈,强调检索质量是上限
- 详解四层优化框架(索引、查询、召回、重排)的系统打法
- 聚焦索引层核心策略,如父子块与摘要索引
许多RAG项目初期常采用“文档切块、向量化、Top-K喂给大模型”的简单流程。演示可行,上线却问题频发:用户换种说法便检索失败;召回大量相似片段,但真正能回答的内容未被排前;上下文不断膨胀,成本上升而答案不稳。真正优化并非仅调整chunk_size或更换Embedding模型,而是将检索拆解为四层:索引层决定知识存储方式,查询层决定问题转换策略,召回层决定搜索路径,重排序层决定最终进入Prompt的证据。
一、检索决定 RAG 的上限
RAG的回答质量,第一步在于检索而非生成。若检索未能找回正确证据,后续更换更强模型或编写更长Prompt,只会让模型更擅长“编造”。唯有检索稳定召回准确内容,生成层才能发挥价值。因此,生产级RAG的核心不是“多拿一点上下文”,而是“拿回该拿的,挡住不该拿的”。这句话看似简单,落地时通常需四层组合实现。
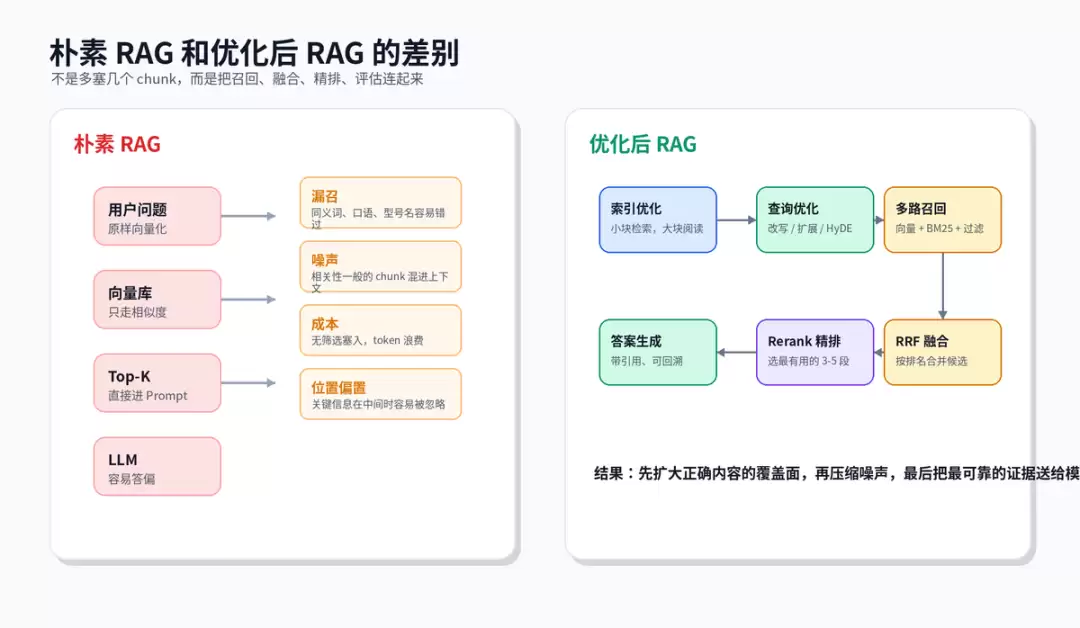
二、四层框架:别零散堆技巧
许多人谈到“检索优化”时会列举调整chunk、更换Embedding、增加Rerank。这些做法都对,但若无法清晰说明各自解决的问题,线上故障时容易陷入盲目试参。更稳健的方式是按层拆解:索引层解决知识粒度,查询层解决表达对齐,召回层解决路径覆盖,重排序层解决候选精度。
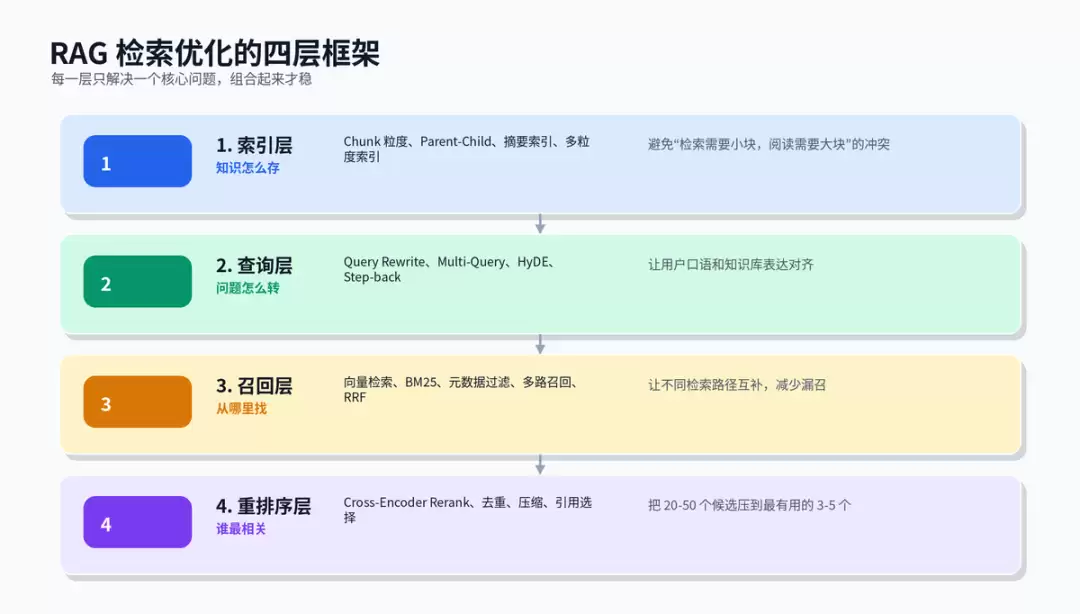
三、索引层:检索用小块,阅读用大块
索引层最易被误解。许多人认为chunk越小越准,但这只说对一半。小块语义聚焦,易被向量检索命中;但小块给LLM后常缺少上下文,模型难以理解前因后果。大块则相反:上下文完整,但一个向量混入过多语义,用户问细节时反而不易命中。这一矛盾正是索引优化的起点:小块负责被找到,大块负责被读懂。
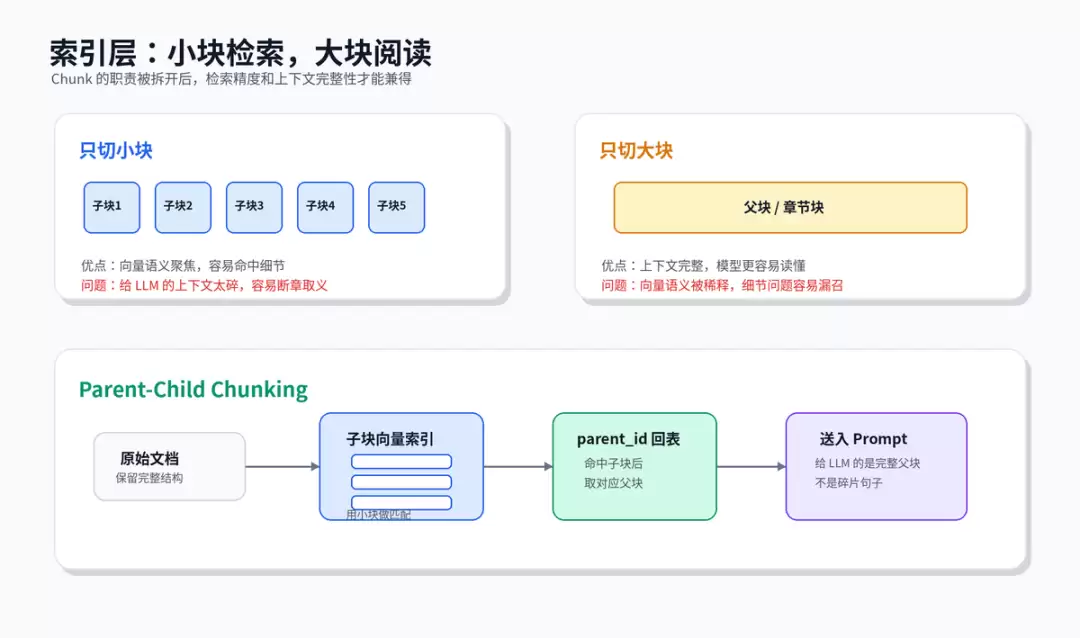
1. Parent-Child Chunking
将文档切为两套粒度:子chunk用于构建向量索引,父chunk用于提供完整上下文。检索时命中子chunk,通过parent_id找到父chunk,再将父chunk交给LLM。此方案适用于客服知识库、制度文档、产品手册、API文档等结构清晰的场景。关键点是父子块需携带版本号和来源信息,否则知识库更新后易出现“子块命中新版本,父块却拿到旧版本”的问题。
2. 摘要索引
部分原文较长且表达分散,直接用原文向量召回不稳定。此时可先为章节或段落生成摘要,用摘要向量构建索引;命中摘要后,再取原文内容供模型阅读。摘要索引的优势在于语义更集中,缺点是可能丢失细节。因此更适合长报告、论文、会议纪要、年报等“章节核心意思明确”的材料。
3. 多粒度索引
同一知识库中,用户问题可能有粗有细。“什么是RAG”适合章节级召回;“退款到账要几个工作日”适合句子级召回。多粒度索引同时保留章节、段落、句子等不同粒度,根据query类型选择召回层级。

四、查询层:把用户问题翻译成“知识库能听懂的话”
索引建得再好,也挡不住用户随口问。用户说“它为什么这么贵”,知识库里写的是“iPhone 15 Pro Max定价策略分析”;用户说“咋退”,知识库里写的是“售后申请流程”。意思相近但表达风格不同,检索就可能漏掉。查询优化就是在检索前对用户query做加工,不是为了美化问题,而是为了让query在向量空间和关键词空间中更容易命中正确文档。
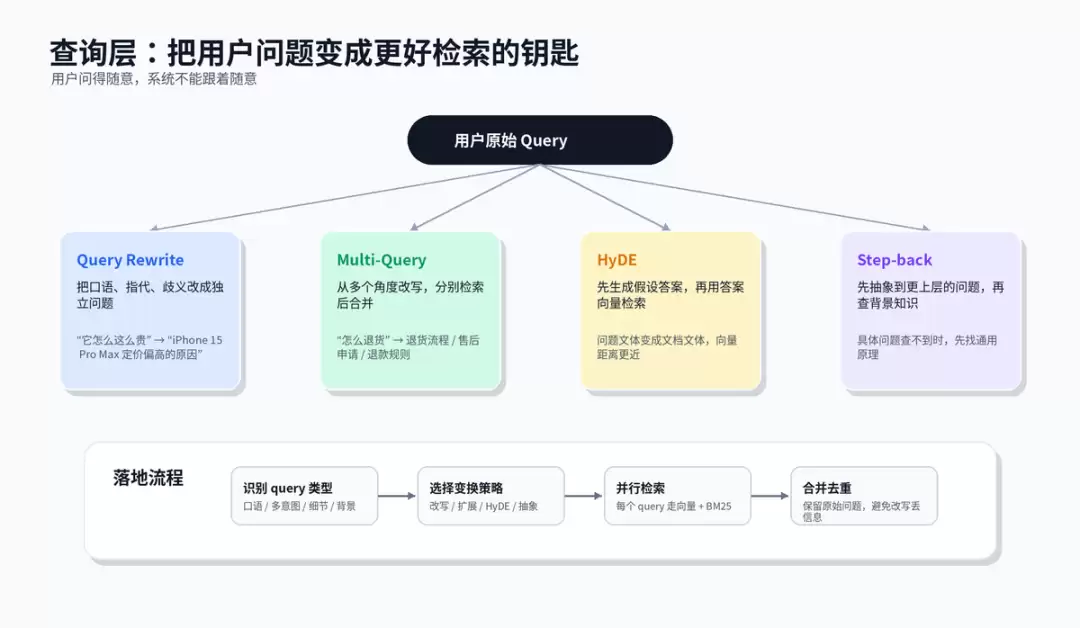
1. Query Rewrite:处理口语和指代
将含糊、口语化、依赖上下文的问题改写成独立、明确、可检索的问题。例如多轮对话中用户追问“这个要多久”,系统需结合上文改写为“退款审核通过后多久到账”。
2. Multi-Query:从多个角度撒网
一个问题可能有多种说法。Multi-Query生成3到5个不同角度的问题,分别检索后合并去重。其价值在于提升召回覆盖率,但需保留原始query,避免改写版本丢失用户的关键细节。
3. HyDE:先生成假设答案,再拿答案去搜
问题是疑问句,文档通常是陈述句。HyDE先让模型基于问题生成一段“可能的答案”,再将该假设答案做Embedding去检索。这样query的文体更接近文档,向量匹配更容易命中。风险在于假设答案方向错误会带偏召回,因此HyDE更适合领域边界清晰、知识库质量较高的场景。
4. Step-back:先问背景,再答细节
当用户问题过于具体,知识库中无完全相同的问法时,可退一步将问题抽象为更通用的背景问题。例如“为什么attention要除以sqrt(d_k)”可先检索“缩放点积注意力的数学原理”,再结合背景回答具体问题。查询改写示例代码下面是一个简化的Multi-Query + RRF伪代码。实际工程中可将query rewrite、检索、融合、去重均设为可观测链路,记录每个query命中的文档,方便排查失败样本。
def retrieve_with_multi_query(user_query, chat_history):queries = llm.generate_queries(original=user_query,history=chat_history,n=4,keep_original=True)all_ranked_lists = []for q in queries:dense_hits = vector_search(q, top_k=20)bm25_hits = keyword_search(q, top_k=20)all_ranked_lists.extend([dense_hits, bm25_hits])fused = rrf_fusion(all_ranked_lists, k=60)deduped = merge_by_source_and_chunk_id(fused)reranked = cross_encoder_rerank(user_query, deduped, top_k=5)return reranked
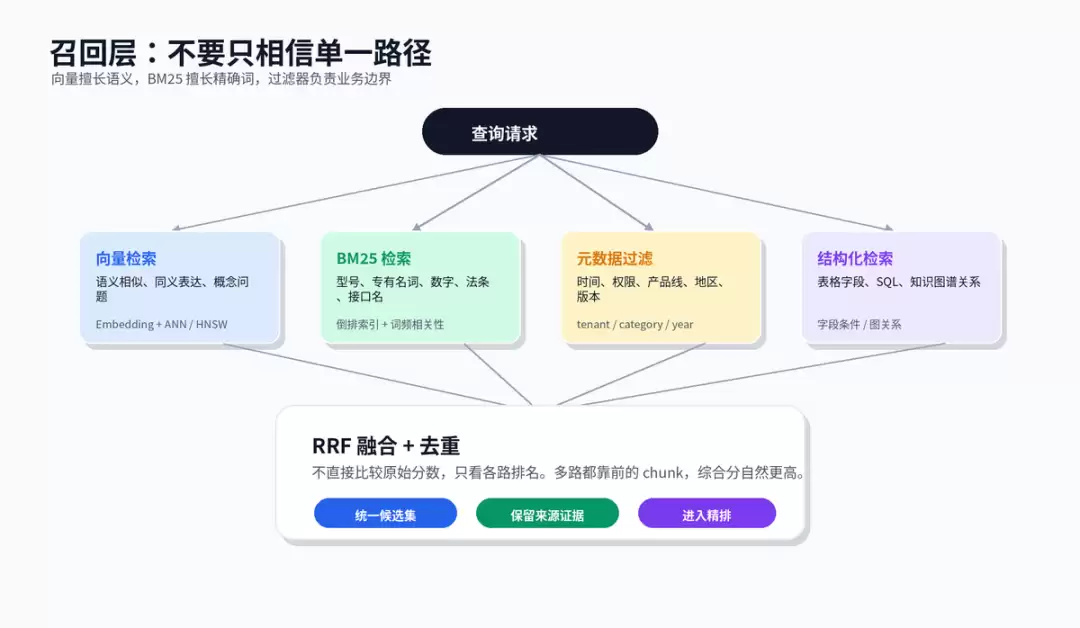
五、召回层:向量检索不是万能的
单独使用向量检索可处理同义表达,但对精确词、型号、数字、接口名、法规条款不一定稳定。单独使用BM25精确匹配强,但无法理解语义。两者并非替代关系,而是互补。生产环境更推荐混合召回:向量检索负责语义相似,BM25负责精确词命中,元数据过滤负责业务边界,必要时再加结构化查询或图关系检索。
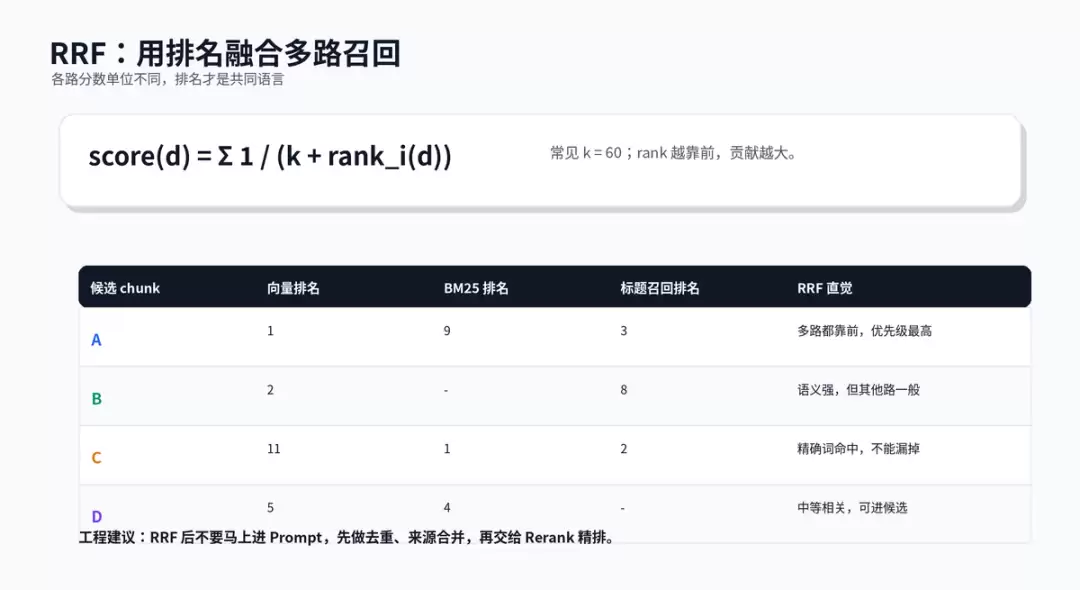
RRF:为什么不用原始分数直接相加
向量相似度、BM25分数、标题召回分数的取值范围差异很大,直接归一化再加权并不稳定。RRF的思路是忽略原始分数,只关注排名。某个chunk在多个列表中排名靠前,其综合分就高。RRF适合工程落地,因为实现简单、无需训练、计算成本低,尤其适用于多路召回后的第一轮融合。
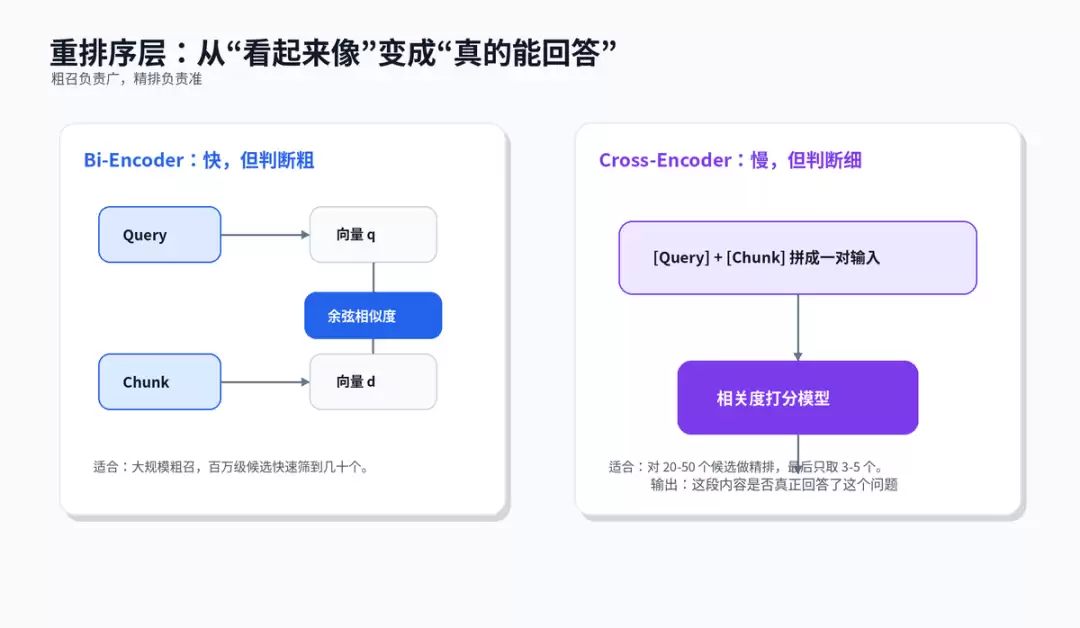
六、重排序层:把候选里的噪声踢出去
多路召回后,候选可能有几十个。最忌讳直接全部塞给LLM。候选越多,token成本越高,噪声越多,模型越易被无关内容干扰。Rerank的作用是精排:粗召阶段用Bi-Encoder快速找到一批可能相关的内容,精排阶段用Cross-Encoder对“query + chunk”逐对判断相关性,最终只将最有用的3到5段送入Prompt。
为什么候选不能无限塞
长上下文模型并不等于“把所有内容扔进去就能找到答案”。已有研究发现,当关键信息处于长上下文中间位置时,模型利用能力可能明显下降;而信息在开头或结尾时,表现往往更好。
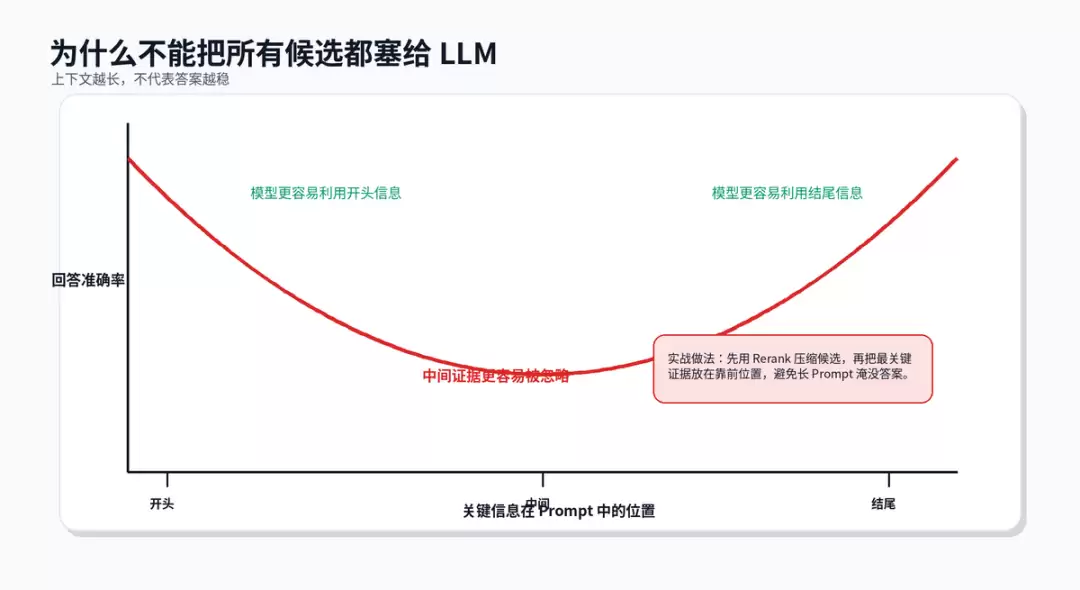
因此重排序后还需控制Prompt组织顺序:最关键的证据放前面,必要的补充证据放后面;同源重复内容合并;冲突证据明确标出来源和时间。
七、生产级组合方案
大多数业务场景无需一上来就堆满所有高级技巧。较稳健的起步方案是:Parent-Child索引 + 向量/BM25混合召回 + RRF融合 + Cross-Encoder Rerank。若用户问题质量很差,再加Query Rewrite和Multi-Query;若文档很长,再加摘要索引和多粒度索引;若业务有权限、时间、地区、产品线边界,务必把元数据过滤纳入检索链路。
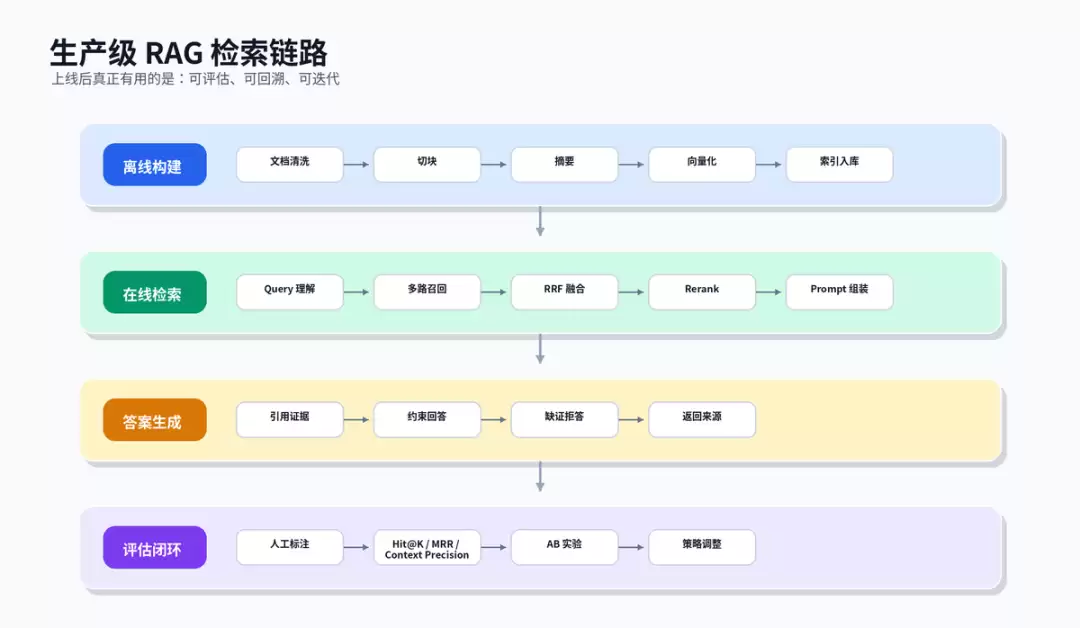
八、优化不要靠感觉,要靠评测集
检索优化最怕“我感觉变好了”。正确做法是准备一批真实问题,为每个问题标注应命中的文档或chunk,再对不同策略做离线评测。常用指标分两类:检索指标看系统是否找回正确证据,如Hit@K、MRR、Recall@K、NDCG;生成指标看答案是否基于上下文,如Faithfulness、Answer Relevancy、Context Precision、Context Recall。
更重要的是失败样本回流。每次用户点踩、人工复核、线上答错,都要能追溯到:原始query是什么,改写query是什么,各路召回了什么,RRF后保留了什么,Rerank为何将某个chunk排前面。只有这样,优化才不是玄学。

九、可以直接落地的检查清单
✓每个chunk都有source_id、doc_id、section、version、time、permission等可追溯字段。✓不要只存向量,保留原文、标题、摘要、元数据,方便混合检索和排障。✓默认启用向量+BM25混合召回,精确词、型号、数字类问题不要只依赖Embedding。✓RRF融合后先去重,再交给Rerank;不要把重复chunk直接塞进Prompt。✓Rerank的top_k不要拍脑袋,结合token预算和评测集调。✓Prompt里放入证据时,优先放最关键、最新、来源权威的内容。✓所有线上回答要记录检索链路,方便复盘“为什么答错”。
十、总结
RAG检索优化是一条完整链路,索引层让知识“存得对”,查询层让问题“问得准”,召回层让候选“捞得全”,重排序层让证据“选得准”。仅调整单个参数可能带来局部提升,但要使系统稳定上线,必须将四层串接起来,并借助评测集和日志闭环持续迭代。RAG的真正能力,不在于模型是否会表达,而在于系统能否将正确证据稳定地送达模型面前。