GEPA 架构拆解:Prompt 和 Skill 优化告别玄学
在Agent系统中,Prompt往往需要多次迭代才能达到理想效果。典型场景是线上问题发生后,人工排查日志与调用记录,手动调整Prompt或Skill,通过评测后保留提升。但这种方式既繁琐又缺乏稳定性。
这个流程虽能运转,但非常疲惫且不可靠。最棘手的并非“改不动”,而是修改A后导致B退化。例如分类更准确了,回复却变得僵硬;检索召回率提升,推理链路却开始乱跳。仅凭一个总分做判断,很容易丢失某些长尾能力。
GEPA 正是针对这类问题而设计。它并非重新打造一套更复杂的手工调参流程,而是将“查看轨迹、定位错误原因、修改Prompt、保留互补版本”这一人工经验,转化为一条可自动运行的进化流水线。
本文从工程视角剖析GEPA:它究竟优化什么,为何比仅依赖分数的Prompt搜索更稳定,以及在业务系统落地时哪些环节最容易被低估。

图:轨迹反馈驱动 Prompt 候选不断进化
Prompt 优化的真实瓶颈:反馈太薄
许多Prompt优化方案最终都会卡在同一个问题上:评测器只返回一个分数。
从61分涨到74分,看起来是进步。但这13分从何而来?哪些样本变好了,哪些变差了?如果一版Prompt更擅长捕捉并发bug,却将一堆低风险diff写成高危告警,是否该保留?
人类调Prompt时并不会只看分数。我们会分析错例,阅读执行轨迹,从失败样本中总结规则。GEPA的起点正是这个判断:LLM已经能读代码、读日志、读用户反馈,那么它也可以读取自己的运行轨迹,并将错误原因写回Prompt。
| 优化方式 | 反馈形式 | 学到的东西 | 常见问题 |
|---|---|---|---|
| 人工手调 | 人读 case 后总结 | 经验规则 | 成本高,难复制 |
| 标量搜索 | 单个分数 | 哪个版本分高 | 不知道为什么好 |
| 强化学习 | reward / rollout | 参数或策略偏好 | 调试成本高,样本消耗大 |
| GEPA | 轨迹 + 自然语言反馈 | 可读、可审计的 Prompt 规则 | 依赖评测器质量 |
这也是GEPA与许多Prompt optimizer的分界线。它并非让模型凭空“想一个更好的提示词”,而是要求模型先读取完整轨迹,再根据具体失败原因进行改写。
Reflective Mutation:把一次失败变成可复用规则
GEPA的变异算子称为Reflective Prompt Mutation。听起来像遗传算法术语,但在工程实现中,它仅包含四个步骤:
- 在训练集中抽取一个minibatch,用当前候选Prompt执行完整链路。
- 保存轨迹,包括模块输入输出、推理过程、工具调用、工具返回和最终答案。
- 评测器给出分数以及文字反馈,例如“定位到了风险但缺少触发路径”或“评论给了结论,却没有最小修复建议”。
- 反思模型读取“旧 Prompt + 轨迹 + 反馈”,仅修改当前选中的模块 Prompt。

图:一次失败如何被反思模型改写成新候选 Prompt
这里有一个实用细节:反思模型通常可以比目标模型更强。它并不直接接管线上任务,而是将诊断能力“写进”目标模型可执行的Prompt中。这样做的成本比训练小得多,产物也更容易审计。
如果目标系统包含多个模块,GEPA不会每次都同时修改整套Prompt。它会选择一个模块进行局部变异,例如只修改分类Prompt,而回复Prompt保持不变。这一限制至关重要:每次只变动一个变量,后续才能知道收益和回归来自哪里。
Pareto 前沿:不要急着扔掉“偏科生”
最容易误解GEPA的地方,在于它并不总是保留总分最高的那一版。
在复合任务中,总分最高的候选未必在所有样本上都占优。它可能在大多数样本上胜出,却在少数关键样本上输得很惨。传统贪心策略会删掉旧版本,导致后续失去从旧分支继续演化的机会。

图:Pareto 前沿保留互补候选,而不是只追最高均分
GEPA利用Pareto前沿维护候选池。判断标准非常简单:只要某个候选在至少一条验证样本上是当前最优,它就有保留的理由。
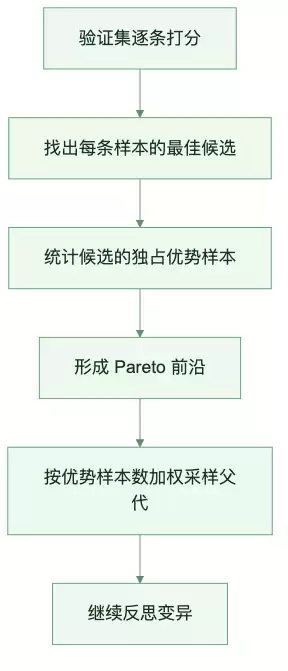
图:按验证样本优势维护候选池,并继续采样演化
这带来了一个实际收益:优化器不会被平均分误导。一个候选只擅长5%的长尾样本,也可能成为后续合并出强版本的材料。
| 候选保留策略 | 会发生什么 | 风险 |
|---|---|---|
| 只留总分最高 | 主干很干净 | 容易丢掉长尾能力 |
| 保留所有历史版本 | 信息完整 | 候选池膨胀,搜索变慢 |
| Pareto 前沿 | 留下互补版本 | 需要稳定验证集 |
我更倾向于将Pareto前沿理解为“能力档案柜”。它并非收集所有旧版本,而是保留那些仍然具有独特价值的版本。
System-Aware Merge:把分支上的好东西拼回来
拥有多条分支之后,GEPA还能完成一项链式优化难以做到的事情:合并。
假设一个Agent包含两个模块:
| 模块 | 职责 |
|---|---|
| L | 在代码 diff 里定位风险点,例如并发、空指针、权限绕过、资源泄露 |
| C | 把风险点写成评审评论,要求有触发条件、影响范围和修复建议 |
第一轮反思可能让L更擅长抓并发问题,但C写出的评论变得像报警器,误伤了可读性。第二轮从旧版本出发,可能把C的语气和证据链调整好了,但L仍然遗漏边界条件。GEPA会在候选谱系中识别这种“同源、互补、互不支配”的关系,然后进行模块级合并。
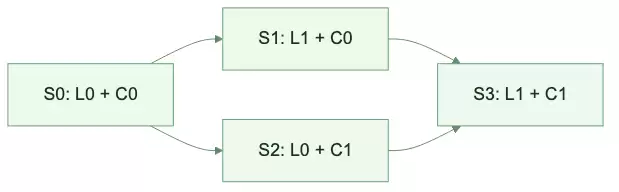
图:同源候选在模块边界清楚时可以横向合并
这并不是简单的复制粘贴。Merge需要满足几个约束:
| 约束 | 含义 |
|---|---|
| 共同祖先 | 只合并同一任务谱系下的候选,避免把无关改动硬拼 |
| 模块边界清楚 | 候选必须能拆成模块级 Prompt 或规则 |
| 验证无回归 | 合并后要重新跑验证集,不能只看局部收益 |
这一步解释了GEPA为何更适合多模块系统。单个Prompt当然也能优化,但在Agent、RAG、工具链、workflow这类系统中,模块之间经常“此消彼长”,Merge的收益会更加明显。

图:多模块 Agent 的分支经验在系统边界内合并
一个代码评审 Agent 例子:高分版本也可能偏科
换一个更贴近工程团队的例子。假设我们在做一个代码评审Agent,它先从diff中找风险点,再生成行级评论。样本来自历史MR,里面有人工标注的真实缺陷、误报和可接受评论。为了防止调参把测试集“看熟”,数据被切成三份:
| 数据集 | 数量 | 用途 |
|---|---|---|
| 轨迹集 | 90 | 每轮抽 12 个 MR,让反思模型看到具体失败过程 |
| 裁判集 | 45 | 所有候选都完整评测,用来决定谁能留在前沿 |
| 封存集 | 30 | 优化期间完全不用,最后看真实泛化 |
初始版本S0只是能跑通链路:
复制代码{
"L": "阅读 diff,找出可能的 bug",
"C": "把发现的问题写成 code review 评论"
}
S0在裁判集上的综合分是61%。第一轮抽到的12个MR中,漏报集中在两类:一是goroutine写共享map未加锁,二是鉴权判断被提前return绕过。反思模型本次只修改L模块,补充“并发写”和“权限短路”两组检查规则,得到S1。
| 候选 | 高风险缺陷召回 | 评论可采纳率 | 综合 |
|---|---|---|---|
| S0: L0 + C0 | 61% | 67% | 61% |
| S1: L1 + C0 | 88% | 54% | 74% |
S1的总分更高,但它有一个很烦的问题:抓得更猛之后,评论中混入了不少“可能有问题”的泛化提醒,人工评审会觉得嘈杂。S0虽然漏缺陷,但在低风险MR上更克制。两者互不支配,都先留下。
第二轮父代采样时,S0被抽中。新minibatch暴露的是评论生成模块的弱项:评论只说“这里可能有空指针”,但未解释触发路径,也不给出修复方法。反思模型本次不修改L,只改C,得到S2。
| 候选 | 缺陷召回 | 评论可采纳率 | 综合 |
|---|---|---|---|
| S0: L0 + C0 | 61% | 67% | 61% |
| S1: L1 + C0 | 88% | 54% | 74% |
| S2: L0 + C1 | 70% | 91% | 82% |
S2基本覆盖了S0的优势,S0可以退出。但S1还不能删除,因为它在高风险缺陷召回上明显更强。此时Merge便有了意义:将S1的定位规则与S2的评论写法拼接起来。
复制代码{
"L": "定位 v1: 显式检查并发写、权限短路、nil 分支和资源释放路径",
"C": "评论 v1: 先给触发条件,再说明影响,最后给最小修改建议"
}
| 候选 | 高风险缺陷召回 | 评论可采纳率 | 综合 |
|---|---|---|---|
| S1: L1 + C0 | 88% | 54% | 74% |
| S2: L0 + C1 | 70% | 91% | 82% |
| S3: L1 + C1 | 87% | 89% | 88% |
后续再跑几轮,最终版本在封存集上拿到86%的综合分。初始S0是59%。更重要的是,人工复核中“评论可直接粘到MR”的比例从41%提升至76%。
这个例子中最值得记住的并非86%,而是S1在那一刻没有被平均分策略清除。它当时的评论质量虽然很差,但缺陷召回这条能力后来被S3继承了。如果只保留S2,系统会变得很会写评论,却继续漏掉真正危险的diff。
GEPA 主循环:搜索的是可解释程序,不是玄学 Prompt
将上述动作串联起来,GEPA的主循环大致如下:
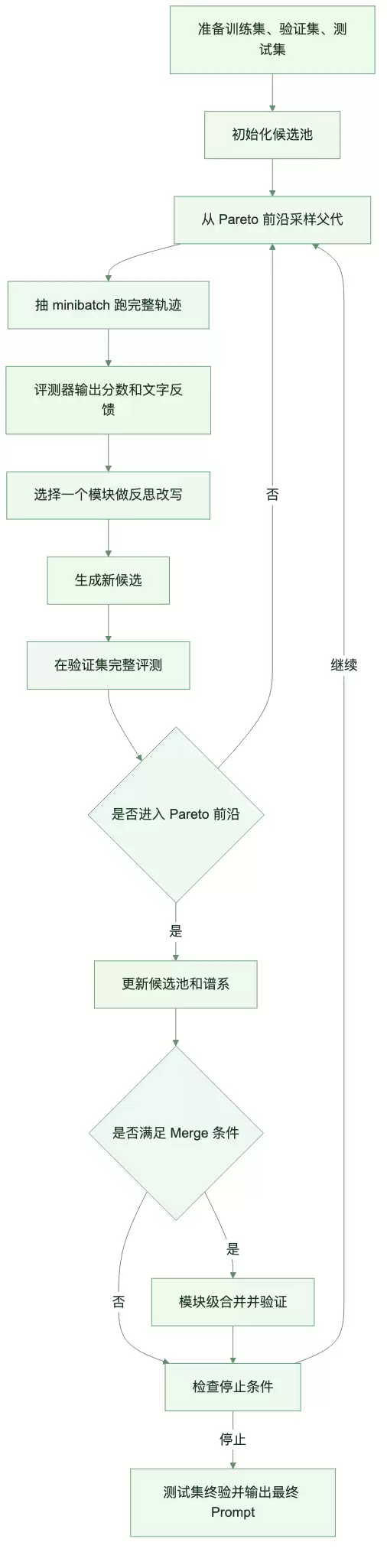
图:从候选采样、轨迹反馈到前沿更新和最终验证
停止条件通常分为三类:
| 停止条件 | 说明 |
|---|---|
| 预算耗尽 | 目标模型调用次数达到 max_metric_calls |
| 前沿饱和 | 连续 K 轮没有新候选进入 Pareto 前沿,K 常用 patience 控制 |
| 满分达成 | 验证集指标达到目标上限 |
这套循环看起来像是搜索,但实际产物更接近一组可解释的文本程序。每次改动都有轨迹、有反馈、有验证分数,也能够追溯是哪个模块发生了变化。
和 GRPO、MIPROv2 比,GEPA 赢在哪里
在HotpotQA、IFBench、HoVer、PUPA等任务上进行了实验。关键信息可以汇总为一张表:
| 对比项 | GEPA | GRPO / RL | MIPROv2 |
|---|---|---|---|
| 平均效果 | 相比基线约 +10 分 | 作为主要对照基线 | 通常低于 GEPA 10%+ |
| 样本消耗 | 通过文字反馈减少无效 rollout | rollout 最多可到 GEPA 的 35 倍 | 与传统 Prompt 搜索接近 |
| AIME-2025 | 相比 MIPROv2 约 +12% | 未作为同表核心项 | 基线 |
| 结果形态 | 自然语言 Prompt,可读可审计 | 策略或参数更新更重 | Prompt 搜索结果 |
GEPA的优势不仅仅在于分数。它的工程吸引力体现在以下几个方面:
| 维度 | GEPA 的处理方式 | 对工程团队的价值 |
|---|---|---|
| 样本效率 | 从单条轨迹里提炼文字规则 | 少跑很多无意义试验 |
| 可解释性 | 知识沉淀在 Prompt 里 | 能审计,也能手工修 |
| 泛化方式 | 学的是规则,不只是分布偏好 | 对长尾样本更友好 |
| 部署成本 | 不需要权重训练 | 主要消耗 API 调用和评测预算 |
| 系统适配 | 支持多模块、谱系和 Merge | 更适合 Agent / RAG / 工具链 |
GEPA还可以作为推理时搜索策略,用于代码优化等任务。也就是说,即使没有训练阶段,只要系统能执行、能反馈、能比较,反思和Pareto前沿也能用来搜索更好的候选解。
从链式迭代到候选树:优化形态变了
传统的Prompt调优大多是一条线:

图:传统 Prompt 调优通常只有一个当前版本
这条线的问题在于,时间上只能有一个“当前版本”。一旦V1被V2覆盖,V1的优势除非人工记录,否则就丢失了。
GEPA更像一棵可以横向焊接的候选树:
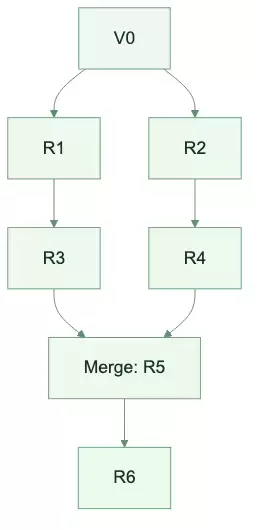
图:GEPA 将线性迭代扩展成可回访、可合并的候选树
这个结构带来了链式迭代所不具备的能力:
| 能力 | 具体含义 |
|---|---|
| 回访分岔点 | 旧候选只要还有独占优势,就能继续作为父代 |
| 横向合并 | 两个分支分别学到的模块经验可以组合 |
| 并行探索 | 多个候选分支可以独立评测和反思 |
这也是我认为GEPA对Agent工程有启发意义的地方。它将“版本”从一个线性编号,转变为一个带有谱系的候选族群。
落地边界:不是所有任务都适合 GEPA
GEPA并非万能。它要求任务能够被执行、被观察、被评价。尤其是评测器,如果只能输出0/1分数,GEPA的效果会大打折扣。
| 适合使用 | 不太适合 |
|---|---|
| Agent、RAG、工具链这类多模块系统 | 只有二值奖励、没有文字反馈的任务 |
| 评测器能解释为什么错 | 验证集太小或噪声太大 |
| 需要白盒、可审计的优化结果 | 目标模型上下文极短,装不下反思规则 |
| 没有 GPU 训练资源,只能调 API | 反思模型预算很低 |
| 贵模型、长链路,对 rollout 成本敏感 | 需要权重级知识注入或风格内化 |
在实际业务中接入GEPA只是第一步。后续通常还有四层工作:
| 层级 | 要做的事 | 代码评审场景例子 |
|---|---|---|
| L1 反馈函数 | 把错因写成自然语言,而不是只给分 | “指出了并发风险,但没有说明哪个共享对象会被两个 goroutine 同时写” |
| L2 参数配置 | 调整 auto、use_merge、num_threads、track_stats 等开关 | 根据验证曲线决定是否开启 Merge 和并行评测 |
| L3 自定义 Adapter | 把业务链路里的工具调用、延迟、复诉率接进轨迹 | GEPA 同时看到 diff 片段、静态扫描结果、人工采纳状态 |
| L4 Instruction Proposer | 约束反思模型如何产出 Prompt | 限制长度,过滤合规风险,多模型投票后再写入 |
这一层层做下去,边际收益会递减,但工程可控性会不断增强。尤其是L1,最容易被低估。评测器写得粗糙,GEPA只是在粗反馈上自动循环。
我对 GEPA 的判断
GEPA让“调Prompt”这件事的重心向上游移动了一截。过去人的主要精力花在修改提示词上,现在更应该花在评测器、轨迹可观测性和反馈粒度上。
这也解释了Claude Code作者Boris的那句话:“I don't prompt Claude anymore. I write loops.”真正重要的不是某条神奇Prompt,而是让Prompt自己变好的循环。循环能走多远,取决于评判信号的细致程度。
GEPA的边界也比PE更广。只要一个对象能文本化、能执行、能打分,它就有机会被反思式进化。Prompt可以,工具描述可以,Skill可以,workflow、路由规则、harness里的约束也可以。
因此,我不太将GEPA看作“自动写Prompt的工具”。它更像一个系统优化框架:将运行轨迹转化为反馈,将反馈转化为文本规则,将文本规则放回系统,再通过Pareto前沿保留那些一时看起来偏科、但可能在未来合并出更强版本的候选。
GEPA为Agent工程提供了更具想象力的优化方向,将重心从纯粹提示词设计转向评测设计、轨迹暴露与失败经验复用,使系统每次迭代都能沉淀可复用的规则。