《从零实现 Agent 系统》连载29:多Agent研究Harness:Lead、Worker与Spawn
本文聚焦Agentium这一开源项目,围绕其Deep Research产品化中的可运营任务链路展开,系统阐述请求流入、分支约束、方向调控与里程碑验收等关键机制。以下内容基于Agentium论文与开源工程的设计,旨在为技术从业者提供可落地的参考。
若正推进Deep Research产品化,这里要回应一个核心问题:Agentium中的研究链路如何构造成可运行的作业——包括请求的流入方式、分支在预算约束下的执行、如何引导方向以及如何验收里程碑。
Agentium参考了DeerFlow、GPT Researcher、Anthropic等编排器–工作器体系的整体形态,在工程层面补齐了SpawnBudget硬闸、全阶段方向审计、租户隔离作业存储以及里程碑持续集成。首先厘清v1、v2、工作流、自主智能体这四条路径,再深入v2全链路。
先把链路跑活
接业务时,先跑通主干请求:开启AGENTIUM_RESEARCH_V2_ENABLED=1,通过聊天分流(POST /v1/chat/messages配合orchestration_mode=research)或控制面直调(POST /v1/research/v2/jobs)创建任务。获取job_id后,查看GET /v1/research/v2/jobs/{id}/events,再通过GET /v1/research/v2/jobs/{id}读取payload.report与payload.graph,复盘时调用.../trajectory。链路跑顺后,后续的DyTopo、人机协作、里程碑才有意义。
一个最小的v2创建负载通常如下:
复制代码{
"query": "请检索并对比近几年 ACL 系列会议与 arXiv 的 multi-agent research 代表论文:列出方法、评测基准、代码可用性与局限,并总结可用于企业 Deep Research Harness 的设计要点。",
"request_id": "req-001",
"trace_id": "trace-001",
"max_workers": 3,
"max_depth": 3,
"spawn_mode": "parallel"
}
上述负载用于建立可观测主干:检查任务是否创建、分支是否发生、合成是否完成,以及失败卡在哪个阶段。
先把几条线分清
在Agentium中,“研究”并非单一实现,以下四个概念各管一层,不可混为一谈:
| 旋钮 | 管什么 | 与研究相关时 |
|---|---|---|
| orchestration_mode(会话级) | 这条消息走对话、固定工作流,还是研究作业 | research→创建v2研究任务(v2开关打开时),返回202,不进入聊天SSE |
| interaction_mode(轮次级) | 本轮工具权限、风险档、是否开启工具循环 | 已走研究分流时基本无意义 |
| v1 DeepResearchPipeline | 固定五段流水线 | 规划→搜索→合成→评审→报告 |
| v2 Research Harness | 领导者–工作器树+作业+图事件 | ResearchLeadLoop+ResearchJobV2Service,本文主体 |
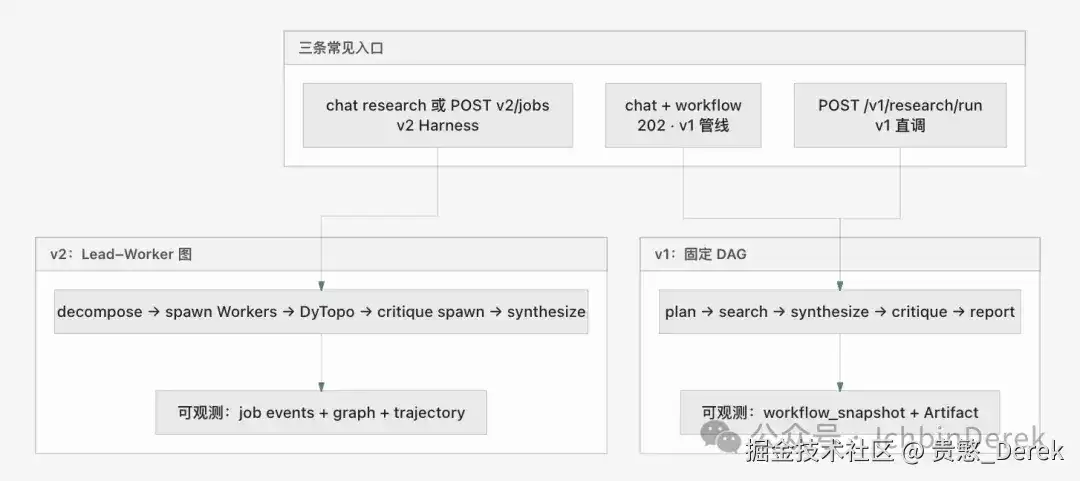
入口方面:POST /v1/chat/messages配合orchestration_mode=research返回202(dispatch: research_job);POST /v1/research/v2/jobs控制面直调,返回200;POST /v1/research/run仍是v1有向无环图。三条入口职责不同,旧版并未消失。
v2总开关AGENTIUM_RESEARCH_V2_ENABLED默认关闭(0)。未开启时v2路由不可用或无法入队;回滚置0,v1仍在。切勿写死全站只有v2。
自主智能体+自动模式是单会话里模型自主调工具;研究框架是后台作业、图SSE、方向队列。工作流是固定有向无环图。三者入口与可观测面不同,混用会带来排障困难。
举一个容易混淆的例子:同样是“ACL+arXiv对比”请求,走聊天research会先获取job_id再看事件流;走research/run直接获取工作流快照;走普通agentic则是会话内流式回复。入口不同,后续的调试面板也完全不同。
v1管线与v2框架:双轨与取舍
仓库中v1与v2双轨并存。v1阶段固定、制品血缘清晰;v2是领导者带工作器的多路检索树,壳层增加了预算、审计与里程碑。
| 维度 | v1DeepResearchPipeline | v2ResearchLeadLoop+框架 |
|---|---|---|
| 编排 | 固定5节点有向无环图 | 领导者分支工作器,可动态拓扑、评审补充分支 |
| 入口 | POST /v1/research/run、命令行 | 聊天research(202)或POST /v1/research/v2/jobs |
| 可观测 | 制品合同、工作流快照 | 图事件总线、轨迹、里程碑 |
| 分解 | plan处理器 | research_think+观测型分解门 |
| 评审 | 有阶段;测试存根常issues=[] | 确定性单轮评审+有限后续分支 |
| 方向 | 无系统化全阶段方向 | POST .../steer+多阶段消费 |
| 并行 | search阶段 | SpawnBudget+分支模式 |
v1适合需要与工作流统一制品、需要确定性有向无环图、未开v2或刻意保持五段流水线的场景。代价是图事件、运营方向、跨作业召回、里程碑与v2不对齐;默认存根下评审几乎不拦截错误。
v2适合多分支研究图、Deep Research工作台、方向/人机协作、里程碑回归、跨任务召回。代价是开关与配置更多;动态拓扑、评审仍为轻量启发式加预算闸,实时里程碑不能与持续集成存根等同。
v1的有向无环图借鉴了Anthropic《Building effective agents》中的工作流优先思路;v2则借鉴了《Multi-agent research system》中的编排器–工作器思路。
下面用同一查询走两条路,对照阶段名与图上节点。示例中的ID、时间戳仅为示意,真实值以作业回包为准。
示例A:v1五段有向无环图
入口有两种:POST /v1/research/run直调,或聊天中orchestration_mode=workflow(同一管线,返回202和workflow_snapshot)。无需开启AGENTIUM_RESEARCH_V2_ENABLED。
请求体示意:
复制代码{
"query": "请检索并对比近几年 ACL 系列会议与 arXiv 的 multi-agent research 代表论文:列出方法、评测基准、代码可用性与局限,并总结可用于企业 Deep Research Harness 的设计要点。",
"request_id": "req-v1-001",
"trace_id": "trace-v1-001"
}
编排为固定五段,没有领导者随时分支的树;并行主要体现在search阶段(由注入的research.search处理器决定扇出),其余按有向无环图顺序执行。
v1没有显式子智能体:plan产出子任务清单,search并行执行。此查询可拆为四步:
- 先拉ACL/EMNLP/NAACL的代表论文,获取方法、任务、年份等基础字段;
- 再补充arXiv的新近工作,防止只看会议信号导致“时间滞后”;
- 单独整理评测基准和代码可用性,避免将“有结果”与“可复现”混为一谈;
- 最后在
synthesize+critique合并,形成对比结论和企业可落地建议。
此链路中没有b1/b2这类显式分支ID。验证“子任务是否执行”通常看两处:plan产物中是否拆出了任务,以及search阶段制品是否覆盖这些拆分项。
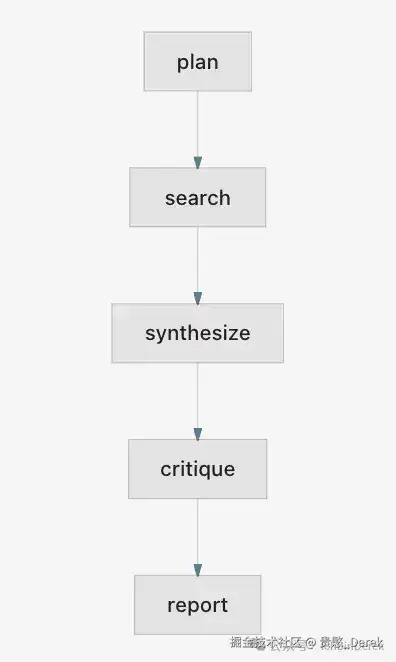
单次pipe.run()内,逻辑顺序大致如下:
| 顺序 | 阶段 | 产物中常见内容 |
|---|---|---|
| 1 | plan | 子主题列表、检索意图(存根处理器时可能是固定模板) |
| 2 | search | 各子主题检索片段;测试环境常为确定性存根 |
| 3 | synthesize | 合并笔记+初步引文 |
| 4 | critique | issues数组;默认存根常为[],很少拦截 |
| 5 | report | report_markdown/摘要;制品ID可沿血缘追溯 |
与v2的差别主要在可观测面:v1没有job_id和图SSE,依赖工作流快照与制品存储;运行中也没有方向插队,纠偏只能改查询重跑或切换v2;分解在plan一次定稿,不会像v2那样动态拓扑、评审再补充分支。
workflow_run或research/run成功时,响应中先看:
复制代码{
"success": true,
"dispatch": "workflow_run",
"run_id": "workflow_run:session-abc:req-v1-001",
"workflow_snapshot": {
"nodes": [
{ "id": "plan", "status": "completed" },
{ "id": "search", "status": "completed" },
{ "id": "synthesize", "status": "completed" },
{ "id": "critique", "status": "completed" },
{ "id": "report", "status": "completed" }
]
}
}
排障时顺着五个节点状态和各阶段制品查看,不要寻找node_added。
示例B:v2领导者–工作器框架
入口:POST /v1/chat/messages+orchestration_mode=research(返回202,dispatch: research_job),或POST /v1/research/v2/jobs(返回200)。需AGENTIUM_RESEARCH_V2_ENABLED=1。
创建作业示意:
复制代码{
"query": "请检索并对比近几年 ACL 系列会议与 arXiv 的 multi-agent research 代表论文:列出方法、评测基准、代码可用性与局限,并总结可用于企业 Deep Research Harness 的设计要点。",
"request_id": "req-v2-001",
"trace_id": "trace-v2-001",
"max_workers": 3,
"max_depth": 3,
"spawn_mode": "parallel"
}
领导者分解→分支工作器→可选动态拓扑加深→评审补充分支→合成;事件写入ResearchGraphEventBus,图上节点逐步生长。
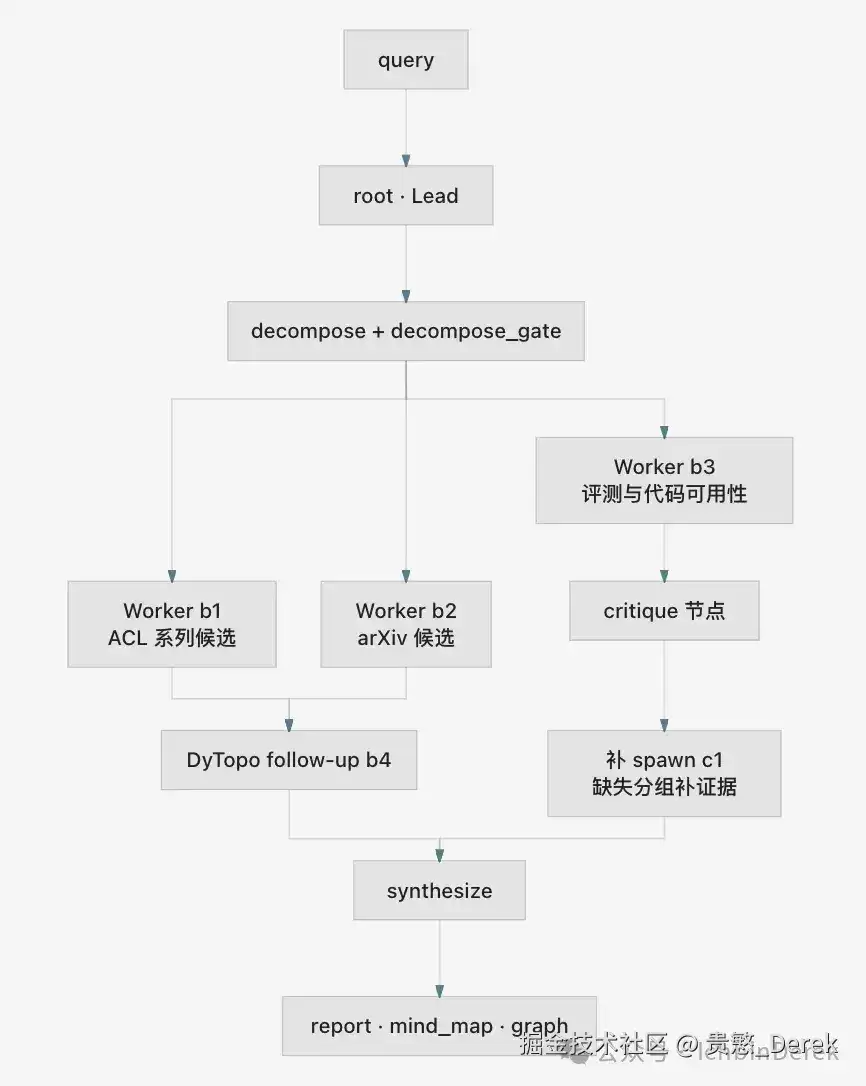
领导者按主题分支工作器,各工作器分别检索。分支分工如下:
b1:汇总ACL/EMNLP/NAACL代表论文,建立会议线索;b2:补充arXiv增量工作,覆盖最新变化;b3:整理基准与代码可用性,单独评估可复现性;b4:动态拓扑后续分支,补齐分支检索后的证据缺口;c1:评审后续分支,在合成前按问题定向补充证据。
对应检索意图:b1偏“会议脉络与代表方法”,b2偏“最新演化与新问题”,b3偏“指标与代码落地”,b4/c1偏“发现缺口后回补证据”。
若发现“该补的分支没补出来”,通常先检查三件事:SpawnBudget是否已满(max_spawn_total/max_depth)、max_dynamic_followups与critique_max_followups是否过低,以及事件流中是否出现steer_consumed、DyTopo.route、critique这三类信号。
异步作业可边拉事件边查看,时间线示意:
| 时刻 | 阶段/事件 | 含义(示意) |
|---|---|---|
| T0 | POST返回job_id=job-7f3a | 作业入队,phase=lead_loop |
| T1 | node_added根节点 | 领导者挂上研究图根节点 |
| T2 | console_line领导者.分解 | 分解出b1/b2/b3(ACL系列/arXiv/评测与代码) |
| T3 | node_statusb1→运行中 | 并行模式下多工作器同时跑arxiv/网页 |
| T4 | Worker(b2).arxiv_q=… | 控制台钩子:实际检索词,用于排障 |
| T5 | node_statusb1→已完成 | WorkerResult带引文、缺口、置信度 |
| T6 | DyTopo.route | 从缺口提取需求/供应,计划后续b4 |
| T7 | critique+issues | 确定性评审发现引用偏少→计划c1 |
| T8 | spawnc1 | 仍受SpawnBudget限制;已满则停止,不会无限补充 |
| T9 | synthesize | integrate_evidence→报告标记 |
| T10 | 作业status=completed | GET .../jobs/{id}读取payload.report+payload.graph |
订阅GET /v1/research/v2/jobs/{id}/events,事件流片段示意:
复制代码{"type": "node_added", "node_id": "b2", "parent": "root", "label": "arXiv 候选"}
{"type": "console_line", "text": "Worker(b2).arxiv_q=multi-agent research arxiv latest"}
{"type": "node_status", "node_id": "b2", "status": "completed"}
{"type": "node_added", "node_id": "c1", "parent": "critique", "label": "citation follow-up"}
{"type": "metrics_snapshot", "spawn_used": 5, "spawn_budget_max": 8}
v2独有的一步是方向插队。假设T3时发现ACL 2024关键论文漏检,调用POST /v1/research/v2/jobs/{id}/steer:
复制代码{ "message": "补查 ACL 2024 多智能体研究及其开源代码可复现性" }
领导者在poll_steer窗口消费后可能分支steer1;审计中需有steer_consumed与spawn_node_id,不能只有方向入队记录。新证据先进入整合再合成,不是修改最终报告的提示词。
并排总览
| 想验证的事 | v1先看 | v2先看 |
|---|---|---|
| 任务是否完成 | workflow_snapshot五节点是否全已完成 | 作业status+图中synthesize是否完成 |
| 检索是否发生 | search阶段制品/处理器日志 | 工作器console_line、引文、缺口 |
| 分解是否合理 | plan输出结构 | quality_gates.decompose、decompose_gate事件 |
| 运营纠偏是否生效 | 无标准方向路径(重跑或切换v2) | steer_events+新分支节点 |
| 质量能否对外宣称 | 真网处理器+人工读报告 | 另跑实时里程碑,勿用存根成绩代替 |
既需要制品血缘简单又需要图上方向,常见做法是简单场景v1直调、工作台用v2;v2开关打开后不会自动替换所有research/run调用方。
一条请求在服务端到底发生了什么
v2(时间线)
将v2请求按时间线展开,动作并不复杂。入口先按orchestration_mode分流,research请求交给ResearchJobV2Service;服务写入作业记录并挂上预算参数、可选召回参数。resolve_spawn_budget算出本次任务的硬闸后,ResearchLeadLoop.run()开始分解、分支、动态加深、评审、合成,图事件持续写入ResearchGraphEventBus。结束后再将report、graph、可选mind_map、evidence_tree回写作业负载,并通过export_trajectory与审计事件完成对账。
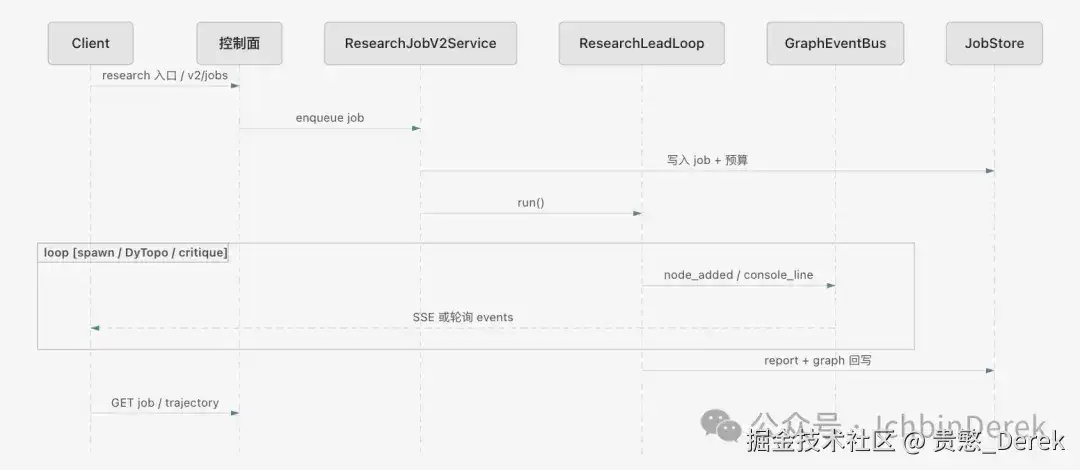
v1(对照时间线)
v1路径更短:一次DeepResearchPipeline.run()在进程内跑完五段,没有独立作业事件总线。
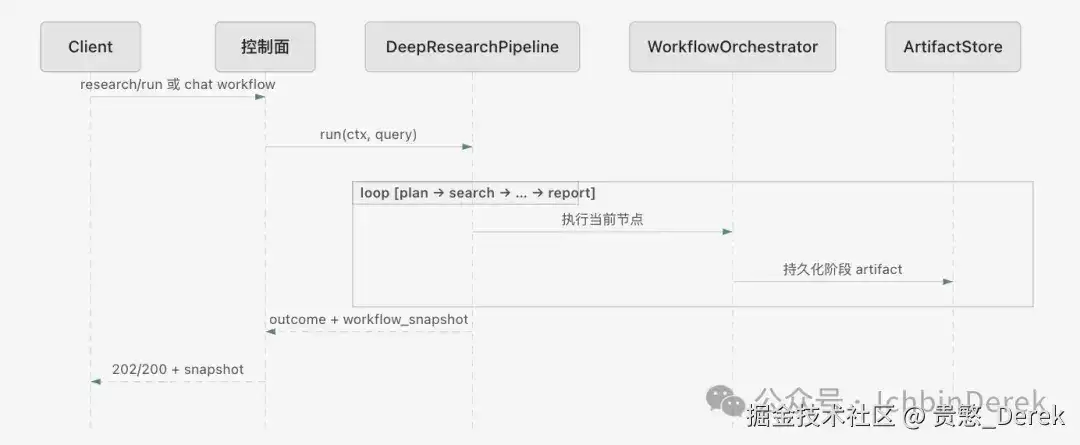
v1没有GET .../events;在响应中获取workflow_snapshot,或事后按run_id查询制品链。聊天workflow与research/run为同一管线,差别在鉴权与会话绑定。
两段流程的价值在于边界清晰:入口、编排、检索、存储、事件各管一块,排障可顺着链路进行,无需在一个巨型函数中猜测状态。
研究图是怎么长出来的
本节聚焦入口与召回。
用户提交orchestration_mode=research(或直调v2作业API)后,控制面不进入聊天SSE——长时间分支、重试、动态后续不适合用一轮对话的token流承载。服务端创建v2作业(job_id、run_id、阶段如lead_loop),挂按作业隔离的事件总线。工作台订阅node_added、node_status、console_line、metrics_snapshot,看到的是根节点→分支→后续/评审→合成,而不是最后一次性吐出长文本。
可选previous_job_id与recall_artifact_ids在领导者入口拼召回前缀(AgentRxiv风格):上一轮报告摘要、制品片段、黑板笔记压入查询。租户不一致时build_recall_prefix整段清空,recall_artifact_ids也会跳过非本租户制品,不能跨租户继续挖掘。
分解:STORM多视角+可选语言模型+质量门禁
领导者第一拍research_think走decompose_query:默认STORM多视角分支(方法/评测/应用等),避免永远三条固定话术;llm_decompose_enabled时可走进程级钩子,失败则回落到确定性分支。
gate_decompose_branches检查分支数量、多样性、是否为遗留固定三联;结果写入last_decompose_gate,图上标记Lead.decompose_gate_failed。门禁失败不会取消作业,仍是观测型:日志中能看见分解质量可疑,领导者仍用已得分支继续分支。运维查看控制台或报告中的quality_gates.decompose,门禁变红不等于停跑。
用本文的论文检索例子就很清楚:同一查询不会只拆成“找论文”这一条,而会至少拆出“ACL系列代表作”“arXiv增量工作”“评测与代码可用性”三路。如果拆出来三路几乎是同义改写(比如都在重复“找最新论文”),decompose门禁会提示多样性不足,提醒先改分解策略,再看后面的检索质量。
工作器:分支检索、缺口与来源校验
工作器不再拆子问题;拆题、分支、合成都在领导者。ResearchWorkerRunner只执行一条SpawnRequest:按标签推断arxiv/网页,构造查询,调用搜索与获取,产出WorkerResult(主题、贡献、引文、缺口、置信度)。需要多层展开,依赖领导者的动态拓扑后续或评审补充分支。
gaps(如no_retrievable_sources)驱动加深与评审后续。source_validate_enabled开启时,低质量引文可过滤并带quality_score。控制台Worker(bN).arxiv_q=…钩子保留,排障时查看实际检索词。
分支执行:并行/顺序/混合+预算
首批分支由execute_spawn_requests按spawn_mode执行:
| 模式 | 行为 |
|---|---|
| parallel | 线程池并行,宽度≤SpawnBudget.max_workers;各分支查询基本独立 |
| sequential | 逐条执行,下一步可携带前序完成分支的片段(便于压测与复现) |
| hybrid | 每批最多max_workers个并行;批与批之间给后续请求带已完成结果的上下文 |
SpawnBudget对所有分支硬顶max_spawn_total、max_depth。初始分支、方向插队、动态拓扑、评审补充分支共用同一账本;动态后续在can_spawn处停止,不会无限增长。
每次分支前经过EmergenceGuardrails(research.spawn)。poll_steer有队列消息时可即时分支方向分支,记入steer_events(阶段、consumed_at、spawn_node_id)。
可用一组固定参数感受差异:max_workers=3, max_spawn_total=8, max_depth=3。parallel会先并行跑3条;sequential是一条跑完再下一条;hybrid会一批并行、一批带上下文继续。无论哪种模式,只要累计分支到8,就会停止继续补充分支。
配置建议:先稳,再快
灰度起步可保守:AGENTIUM_RESEARCH_V2_ENABLED先在开发或灰度打开,AGENTIUM_RESEARCH_V2_SPAWN_MODE用parallel,max_workers从2~4起步,max_depth先2~3;AGENTIUM_RESEARCH_DYNAMIC_ROUTING默认开启,critique_max_followups先1或2,human_feedback_mode从minimal起步。
并行、动态加深、评审一起拉满时,预算撞墙、检索不足、审批拖住任务会叠加在一起,难以区分。先把失败路径跑顺,再逐项加量。
动态拓扑与评审:不是第二个领导者,也不是辩论智能体
分支完成后,若dynamic_routing_enabled,仍是同一个领导者循环做轻量路由:从各WorkerResult提取需求/供应,用token重叠画语义边(DyTopo.route),再plan_dynamic_spawn_chain在max_dynamic_hops×max_dynamic_followups内分支后续。不会另起一个编排智能体;实现上是词重叠路由,正文不展开算法。
合成前是单轮确定性评审(run_deterministic_critique):检查整合后有无事实、缺口/冲突、分支是否完成,没有第二个语言模型互辩。问题经plan_critique_followups转为补充分支(受critique_max_followups与SpawnBudget限制),图上出现评审节点。
可选_maybe_run_code_experiment在安全沙箱下运行受控实验节点,失败记为分支失败。
动态拓扑补充“缺失的那块证据”;评审是合成前清单复核,缺口大时再补一两个定向分支,避免扩成无限递归辩论。
方向与人机检查点
ResearchJobV2Service.steer将纠偏文案入队(作业须运行中/取消中)。方向会改变检索路径,不只修改报告措辞:poll_steer在分支中可插队新分支;后分支、预合成、预评审等阶段也会_consume_phase_steer。新证据先进入integrate_evidence,再影响合成。
human_feedback_mode(minimal/each_phase/each_critique)可在分解、合成、评审前走批准门,与治理对齐。未注入批准服务时检查点标记为hitl_service_unavailable。
同一句方向在不同阶段效果不同:分支阶段更像新增并行检索;预合成像合成前补充证据;预评审像先补齐再复核。
收束:整合证据、导图与制品
synthesize_report先integrate_branch_evidence,再合成摘要、报告标记、引文(带citation_indices)。gate_synthesis_report可检查摘要长度与引用是否达标。
报告负载还可包含思维导图、证据树(长报告按evidence_tree_min_tokens折叠)、评审元数据。大段分支正文经maybe_offload_branch_text进入制品存储(连载08)。任务完成返回报告+图快照;支持export_trajectory导出脱敏轨迹。摘要供快速阅读,引文供对账,思维导图/证据树供结构化复盘。
共享黑板、技能与系统评测
黑板(SharedWorkspaceMemory)是多分支工作器共用的带租约共享白板,在同一研究任务中共享进度、交接摘要和待补证据。声明/发布/读取与召回前缀配合,适用于进程内框架;跨Pod并非自动分布,跨实例恢复需结合检查点/交接。无租约发布会被拒绝。
skills/deep-research提供提示词与模板边界;运行时以领导者/工作器代码路径为准。
里程碑脚本run_research_milestone_eval.py三档语义不同:存根使用假工作器、不打网;golden读取固定数据;live真检索。CI默认存根门(如milestone_pass_rate ≥ 0.8),存根变绿不能等同live达标。对外宣称生产检索质量,须显式跑live并查看分支效率、引用覆盖、耗时等关键指标。
线上排障,别先怪模型
线上不要先盯最终报告责怪模型。顺着框架倒推:入口是否为research作业、事件是否在增长、预算是否撞墙、分解门与评审问题、方向是否steer_consumed、live评测是否支撑质量判断。
按此顺序,5分钟内通常能定位大头:事件是否还在增长、预算是否打满、分解/评审信号是否正常,最后才看提示词。先确认壳层可控,再调整策略;否则改提示词重跑,可能只是预算早已打满。
与外部深研产品的差异(一句)
业界常见的规划→多路检索→报告,Agentium同样参考;差异在于SpawnBudget、全阶段方向审计、租户作业存储、里程碑CI是否写进运行时,而不是多堆智能体角色名。
几个高频误区
最常见的坑是接入层:把research当作聊天SSE接入,而不是消费作业事件API;把分解门当作阻断器,看到红灯就以为任务会停。还有预算判断:以为动态后续会一直加深,但max_spawn_total和max_depth会先堵住路。
另两类误判也很常见:方向只看到入队、没核对steer_consumed;存根里程碑一绿就当live达标。再加上忘了开v2开关就认定功能坏了,最后看起来像模型问题,其实是链路理解没对齐。
收束一下,下一篇讲什么
v2框架将STORM/语言模型分解、观测型门禁、分支模式、工作器检索、动态拓扑、评审补充分支、方向/人机协作、证据整合与思维导图收进ResearchJobV2Service,与orchestration_mode=research对齐;与v1五段有向无环图双轨并存,按场景选型。入口与工作流、自主智能体三分法一并记住,减少混线。
下一篇进入资源管理:MCP、技能、角色的登记、探测与WorkspaceAgentConfig绑定。