skill 的终局是 agent 化:我给 SKILL.md 写了个编译器:6 个 Harness 把散文孵化成独立 Agent
历时三个月,我打造了一款名为agenthatch的编译器,它能够将markdown格式的skill文档编译成具备类型签名和状态机的Python Agent,支持pip安装和独立运行。以下是这个项目的完整解析和设计思考。
先说结论(怕你划走)
我用了三个月时间,给 SKILL.md 编写了一个编译器,它的名字是agenthatch。
这个编译器只做一件事:把一个用 markdown 编写的 skill,编译成一个能够通过pip install安装、可以独立运行、并且带有类型签名和状态机的 Python Agent。
它既不是 prompt wrapper,也不是 RAG 套壳,而是实实在在的代码生成——pyproject.toml、agent.py、tools.py、runtime.toml,一整套文件齐全,运行起来就是一个正式的 Python 包。
pip install agenthatch
agenthatch init
agenthatch skills add ./my-skill/SKILL.md
agenthatch hatch my-skill # 编译
agenthatch run my-skill # 运行
只需三条命令,就能将 markdown 文件转化为一个正在运行的 agent。
项目仓库地址为:github.com/agenthatch/…
以下内容将详细说明为什么做这件事、具体怎么做、以及在这个过程中踩了哪些坑。这不是一篇翻 README 的水文,每个关键点都附带了源码位置,你可以自行验证。
一、起源:Claude Code 把我写的 skill 当厕纸翻了
我是 EternalRights,一名智能体开发工程师,曾在滴滴和 CodeFlying 从事 agent 相关工作。
今年四月份,全公司都在力推 skill 开发。各个团队都在编写——测试的、部署的、代码审查的,热潮如同抢鸡蛋一般。我也写了一个,将自己负责的 agent 开发工作全部封装进去:每个 API 端点如何调用、MCP 如何配置、token 在什么场景下不够用、几个月来踩坑积累的经验规则——事无巨细地写进一个 SKILL.md 文件,作为工作交付物提交了上去。
随后,我眼睁睁地看着 Claude Code 运行它。
我编写的那些严格要求——"必须先检查环境变量"、"遇到 X 类型错误立即退出"——模型仿佛视而不见。它把这份 skill 当作一本参考书,而非操作规范。每次运行时,理解都会出现偏差。有一次,它几乎让一个本应在测试环境就被拦截的问题溜进了生产环境。
我倾注心血编写的内容,在它手里就像一段可以被选择性忽略的散文。
你知道那种感受吗?你提交了一份自认为严谨的成果,但执行它的"大脑"却根本不尊重它。
那天晚上,一个特别朴素的想法冒了出来:skill 不应该被"解读",它应该被"编译"。
二、范式的坑在哪:SKILL.md 本质是散文
我先把这个问题的本质说清楚,不和你扯虚的。
一个 SKILL.md 文件的本质是什么?是一段散文。人类写给人类看的散文。 然后你把它塞进 system prompt,让 LLM 在运行时自己去猜测这段文字到底要求它做什么。
一两个 skill 还行。三个?勉强凑合。超过五个?问题就开始显现了。
| 痛点 | 实际发生了什么 |
|---|---|
| 零隔离 | 所有 skill 都拥挤在同一个 context window 里。一个文件整理 skill 的逻辑,可能会错误地嫁接到 git 操作上,最终输出一个四不像的结果。 |
| 参考书,不是操作手册 | Agent 将 SKILL.md 视为一个松散的建议,而非具有约束力的契约。面对较长的 skill,它会跳读,只挑选看起来相关的部分,忽略剩余内容。 |
| Token 浪费 | 每个 SKILL.md 都永久驻留在 system prompt 中。如果有 5 个 skill,每个 3KB,那么在开口对话之前,上下文就已经消耗了 15KB。对于长任务而言,这个问题会呈指数级恶化。 |
| 零校验 | 工具名称拼写错误、参数缺失、指令存在歧义——agent 一个都抓不住,全部留到 runtime 才暴露。等到问题爆发时,对话往往已经进行了 20 轮之多。 |
| 规模衰减 | 1 到 3 个 skill 时还能使用,一旦超过 10 个就会失控。没有依赖图,没有冲突检测,完全不清楚谁覆盖了谁。 |
这并非 Anthropic 的 bug,也不是你的 skill 写得不好。这是架构层面上的衰减——一个 LLM 在同一段上下文里解读七份彼此零隔离的散文,且每次解读结果都不相同。
打个比方:你让一个人同时阅读七本操作手册,每次问他问题,他都需要从头翻阅这七本书来拼凑答案。这个人迟早会崩溃。LLM 也是如此。
核心问题不在于格式。问题在于 SKILL.md 属于 prompt engineering 范畴,而非 software engineering。你在让 LLM 在运行时去解读人类编写的散文,没有编译过程,没有类型检查,更没有契约。
三、范式反转:skill 的终局是 agent 化
这是我整篇文章最想让你记住的一句话,也是我做这个项目的底层逻辑:
下面展开来讲。
现在所有人都在编写 skill,写给 Claude Code、写给 Codex CLI、写给 OpenClaw。然而,在这些工具中,skill 的角色是什么?是一段被塞进 system prompt 的散文,由 LLM 在运行时反复解读。 skill 只是 prompt 的一部分,永远依附于某个 host agent。
这个范式是有问题的。skill 不应该是 prompt 的附属品,skill 应该是 agent 的源码。
你想想,Java 源码被编译成字节码由 JVM 运行,TypeScript 被编译成 JavaScript 由浏览器运行。编译这一步,在运行之前就将人类的表达转化成了机器能够确定性执行的格式——在编译时捕捉 typo,进行类型检查,消除歧义。
skill 缺少的正是这一步。它没有编译过程,而是直接将散文原封不动地交给 LLM,让 LLM 每次都自己去猜测含义。
因此,skill 的终局不是"写得更好",而是"被编译成 agent"。 skill 不应该是 host agent 的 prompt 配件,它应当是 agent 的孵化输入——你编写 skill,编译器将其孵化成一个独立的agent。
这就是 agenthatch 所做的事情。它并非 skill 的替代品(你的 skill 该怎么写还怎么写),也不是 Claude Code 的替代品(生成的 agent 可以完全独立运行)。它是连接这两者的中间环节:将散文转化为可执行代码。 就好比javac之于.java,tsc之于.ts,agenthatch 之于SKILL.md。
一旦想通这一点,许多事情就顺畅了:
- skill 不再死守在 system prompt 里消耗 token,编译后运行时只占用约 150 字节的配置
- 每个 skill 都被编译成独立的 agent,实现天然隔离,不再互相污染
- 编译时进行 schema 校验,typo 和歧义在编译期就被捕捉,不会留到 runtime
- 生成的 agent 能够
pip install、能够import、能够独立运行,不依赖任何 host
四、三阶段管线:不跟你扯虚的,源码在这
agenthatch 的核心是一条三阶段管线:
SKILL.md → Parse → 6-Harness LLM Pipeline → Code Generation → Runnable Agent
(输入) (Phase 1) (Phase 2: AI 推理) (Phase 3: Jinja2) (输出)
我会逐一讲解,并附上源码位置,方便你去查阅。
Phase 1:确定性解析,零 AI
Phase 1 完全不使用 AI。它直接将 SKILL.md 的 frontmatter、正文以及目录文件拆解出来。这是一个确定性操作,不存在 AI 带来的随机性。
入口位于 parser.py 文件的assemble_context()函数中:
def assemble_context(skill_path: str | Path) -> ContextPack:
# Step 1: 路径解析 → dir_name
skill_dir = _resolve_skill_directory(Path(skill_path))
dir_name = skill_dir.name
# Step 2: 文件发现 → FileManifest(SHA-256 + 全文内容)
manifest = _discover_files(skill_dir)
# Step 3: YAML best-effort 解析 → frontmatter dict | body raw
frontmatter, body, warnings = _best_effort_parse_yaml(skill_dir)
return ContextPack(frontmatter, body, manifest, dir_name, warnings, skill_dir)
关键设计理念:Phase 1 不做任何语义判断。文件是脚本、文档还是配置,Phase 1 不会去猜测——那是 Phase 2 的任务。Phase 1 只负责读取字节、计算 SHA-256 哈希值、进行 YAML 解析。
v0.8 版本增加了一个 Phase 1.5 的ScriptAnalyzer,它使用 AST 解析 Python 脚本,使用正则表达式解析 shell 脚本,用于提取函数签名。这一步同样是确定性的,其输出会喂给 Phase 2 的 Harness C,用于进行精确的接口推理。凡是能用确定性方法解决的问题,就绝不麻烦 LLM。
Phase 2:6 个 AI Harness 并行推理
这是整个项目的核心。六个专门化的 AI Harness 负责处理 skill,每个都有自己独有的 persona 和温度设置。
温度配置表在 engine.py 文件中是硬编码的,我直接贴出来:
HARNESS_CONFIG: dict[str, dict[str, type | Any]]] = {
"A": {"thinking": True, "temperature": 0.1,
"reason": "Identity extraction is deterministic — low temp for consistency"},
"B": {"thinking": True, "temperature": 0.5,
"reason": "Intent inference requires creativity for long-tail triggers"},
"C": {"thinking": True, "temperature": 0.5,
"reason": "Interface inference is complex — needs SKILL.md + ScriptManifest"},
"D": {"thinking": True, "temperature": 0.3,
"reason": "Base detection needs precision — moderate temp"},
"E": {"thinking": True, "temperature": 0.2,
"reason": "Assembly validation is structured — low temp for consistency"},
"F": {"thinking": True, "temperature": 0.3,
"reason": "MCP config extraction needs exact matching — moderate temp"},
}
每个温度值都不是随意决定的,都附有理由。Identity 提取是确定性的,温度被压低到 0.1;Intent 推理需要覆盖长尾触发词,需要一定创造力,因此设为 0.5;Assembly 校验是结构化的,温度压到 0.2。
六个 Harness 各自负责一项任务:
| Harness | 职责 | 模型档位 | 温度 |
|---|---|---|---|
| A — Identity | 从 frontmatter 提取 name/version/description | small | 0.1 |
| B — Intent | 推理触发词和用户意图 | small | 0.5 |
| C — Interface | 设计工具签名、参数、返回类型 | large | 0.5 |
| D — Base | 检测运行时基类和指令结构 | large | 0.3 |
| E — Assembly | 交叉校验其他五个输出,产出 AHSSPEC | small | 0.2 |
| F — MCP | 检测并配置 MCP server 连接 | small | 0.3 |
为什么要拆分成六个?因为我尝试过一个超大 prompt 搞定一切,但输出结果就像抽奖一样不靠谱。 拆分开来之后,每个只管一件事,质量提升了不止一个档次。这与编译器将前端拆解为 lexer/parser/semantic 是同一个道理——遵循单一职责原则。
每个 Harness 都执行一个Analyze → Infer → Self-Validate → Correct 的循环,最多进行两次内部重试。该循环的实现位于 engine.py 文件的AgentHarness.run()方法中:
def run(self, **inputs: object) -> HarnessOutput:
"""Execute Analyze → Infer → Self-Validate → Correct loop."""
reasoning: list[str] = []
degradations: list[str] = []
retries = 0
system = self.build_system_prompt()
user = self.build_user_message(**inputs)
messages = [{"role": "system", "content": system},
{"role": "user", "content": user}]
reasoning.append(f"[{self.name}] analyze: inputs received")
# Step 1: 初始推理
result = self._infer(messages)
reasoning.append(f"[{self.name}] infer: output received, {len(str(result))} chars")
# Step 2: 自校验 + 纠错循环
while retries <= self.max_internal_retries:
passed, reason = self.validate_output(result)
if passed:
reasoning.append(f"[{self.name}] self_validate: passed")
break
reasoning.append(f"[{self.name}] self_validate: failed — {reason}")
if retries >= self.max_internal_retries:
degradations.append(reason)
break
result = self.correct_on_failure(result, reason, **inputs)
retries += 1
confidence = self._estimate_confidence(result, degradations, retries)
return HarnessOutput(result, confidence, reasoning, ...)
每个 Harness 都拥有自己的validate_output()方法。例如,Harness A 会校验 identity.id 必须符合 kebab-case 格式:
def validate_output(self, result: dict[str, Any]) -> tuple[bool, str]:
identity = result.get("identity", {})
identity_id = identity.get("id", "")
if not identity_id:
return False, "identity.id is empty"
if not re.match(r"^[a-z0-9]+(-[a-z0-9]+)*$", identity_id):
return False, f"identity.id '{identity_id}' is not kebab-case"
if not identity.get("display_name"):
return False, "identity.display_name is empty"
return True, ""
Harness B 会校验 triggers 的数量必须在 [5, 15] 之间,satisfies 必须在 [3, 8] 之间,summary 至少需要 20 个字符。这些约束并非由 LLM 自行决定,而是通过代码强制执行的。 一旦 LLM 的输出不符合规范,就会立即被退回重做。
E 是最关键的——它负责校验其他五个 Harness 的输出,并生成统一的 AHSSPEC(Agent Hatch Standard Specification)。E 还会计算一个结构性置信度,这个置信度并非 LLM 的自我评估,而是通过代码计算得出的数值:
def _compute_structural_confidence(self, ahs_dict: dict[str, Any]) -> float:
checks = 0
passed = 0
id_ = ahs_dict.get("identity", {})
for f in ("id", "display_name", "version"):
checks += 1
if id_.get(f): passed += 1
iface = ahs_dict.get("interface", {})
for f in ("provides", "requires"):
checks += 1
if iface.get(f): passed += 1
# ... 继续数 instructions、resources
score = round(passed / max(checks, 1), 2)
return score
我不相信 LLM 自我评估的 confidence,我只相信代码通过计数得出的结果。 这是一个非常重要的设计决策。
还有一个值得注意的细节:Orchestrator 在分派 Harness 之前,会先进行一次预飞分类,根据 skill 的类型来决定每个 Harness 应该使用哪个模型档位。分类逻辑位于_classify()函数中:
def _classify(self, context: ContextPack) -> str:
_SCRIPT_SUFFIXES = {".py", ".sh", ".js", ".ts", ".rb", ".go", ".rs"}
has_scripts = any(Path(e.path).suffix.lower() in _SCRIPT_SUFFIXES
for e in context.file_manifest.entries)
body_lower = context.body.lower()
api_indicators = ["api", "oauth", "token", "http", "rest", "webhook"]
has_api = any(ind in body_lower for ind in api_indicators)
if has_scripts and has_api: return "integration"
if has_scripts: return "script_driven"
if len(entries) > 2: return "knowledge"
return "pure_instruction"
四种 skill 类型对应四套不同的模型档位组合。对于纯指令类的 skill D,直接跳过(无需检测基类),以节省 token;对于集成类的 skill,则全部使用 large 模型。并非所有 skill 都值得动用大模型,预飞分类能帮你节省成本。
Phase 3:Jinja2 把 spec 渲染成完整 Python 包
Phase 3 负责代码生成。Jinja2 模板将 AHSSPEC 渲染成一个完整的 Python agent 包:
hatched-agent/
├── pyproject.toml # pip-installable 包
├── runtime.toml # LLM provider、model、API keys
├── README.md # 生成的使用文档
├── agenthatch.yaml # AHSSPEC manifest
└── src/{package_name}/
├── __init__.py
├── agent.py # Agent 类(继承 AHCoreAgent)
├── tools.py # 类型注解的工具实现
└── references.py # AI 提取的结构化数据
引擎位于 generate/engine.py 文件中的GenerateEngine类。模板映射非常直观:
TEMPLATE_MAP: dict[str, str] = {
"pyproject.toml.j2": "pyproject.toml",
"agent.py.j2": "src/{package_name}/agent.py",
"tools.py.j2": "src/{package_name}/tools.py",
"references.py.j2": "src/{package_name}/references.py",
"runtime.toml.j2": "runtime.toml",
"README.md.j2": "README.md",
}
最终生成的产物能够pip install,能够import,并且能够独立运行。这次是真正的 agent,而不是套了一层皮的 prompt。
Runtime:PlanLayer 六状态机
生成的 agent 在运行时并非采用裸的 ReAct 循环,而是带有一个PlanLayer 状态机——一个六状态规划引擎。状态定义在 plan.py 文件中:
class AgentState(str, Enum):
STARTING = "starting" # 初始状态,等计划
PLANNING = "planning" # 正在生成/更新计划
EXECUTING = "executing" # 正在执行计划步骤
VERIFYING = "verifying" # 正在校验结果
REPLANNING = "replanning" # 遇到阻塞,正在修订计划
DONE = "done" # 终态——所有步骤完成
运行方式是:agent 启动时,首先通过一个虚拟的plan工具生成结构化计划,然后按照计划步骤执行,每一步都有显式的状态跟踪。当遇到连续工具失败或步骤阻塞时,会触发 replanning。状态转换是由循环控制的,而不是由 LLM 控制——这一点至关重要,因为 LLM 不可靠,而状态机是可靠的。
计划会被渲染成文本并注入到 system prompt 中,agent 可以自己看到进度:
## Plan: 给项目加国际化
Step 1: 安装 next-intl
▶ Step 2: 创建语言包
Step 3: 配置 middleware
Progress: 1/3 steps done
五、实战:从 SKILL.md 到运行中的 Agent
光说不练假把式。下面用一个真实的 skill 来演示整个过程。
Step 1:写 SKILL.md
---
name: weather-advisor
description: 查询全球任意城市天气,支持多日预报和穿衣建议
version: 0.1.0
---# Weather Advisor Agent## 能力
- 查询指定城市的实时天气
- 查询未来 3 天天气预报
- 根据天气给出穿衣建议## 工具
- httpx 调用 OpenWeatherMap API
- rich 彩色格式化输出## 工作流程
1. 接收用户输入的城市名
2. 调用 OpenWeatherMap API 获取天气数据
3. 解析 JSON 响应,提取关键信息
4. 用 rich 格式化输出
5. 根据温度给出穿衣建议
这就是一个普通的 markdown 文件。没有一行代码,没有工具签名,没有类型。 全都是散文。
Step 2:编译
agenthatch skills add ./weather-advisor/SKILL.md
agenthatch hatch weather-advisor
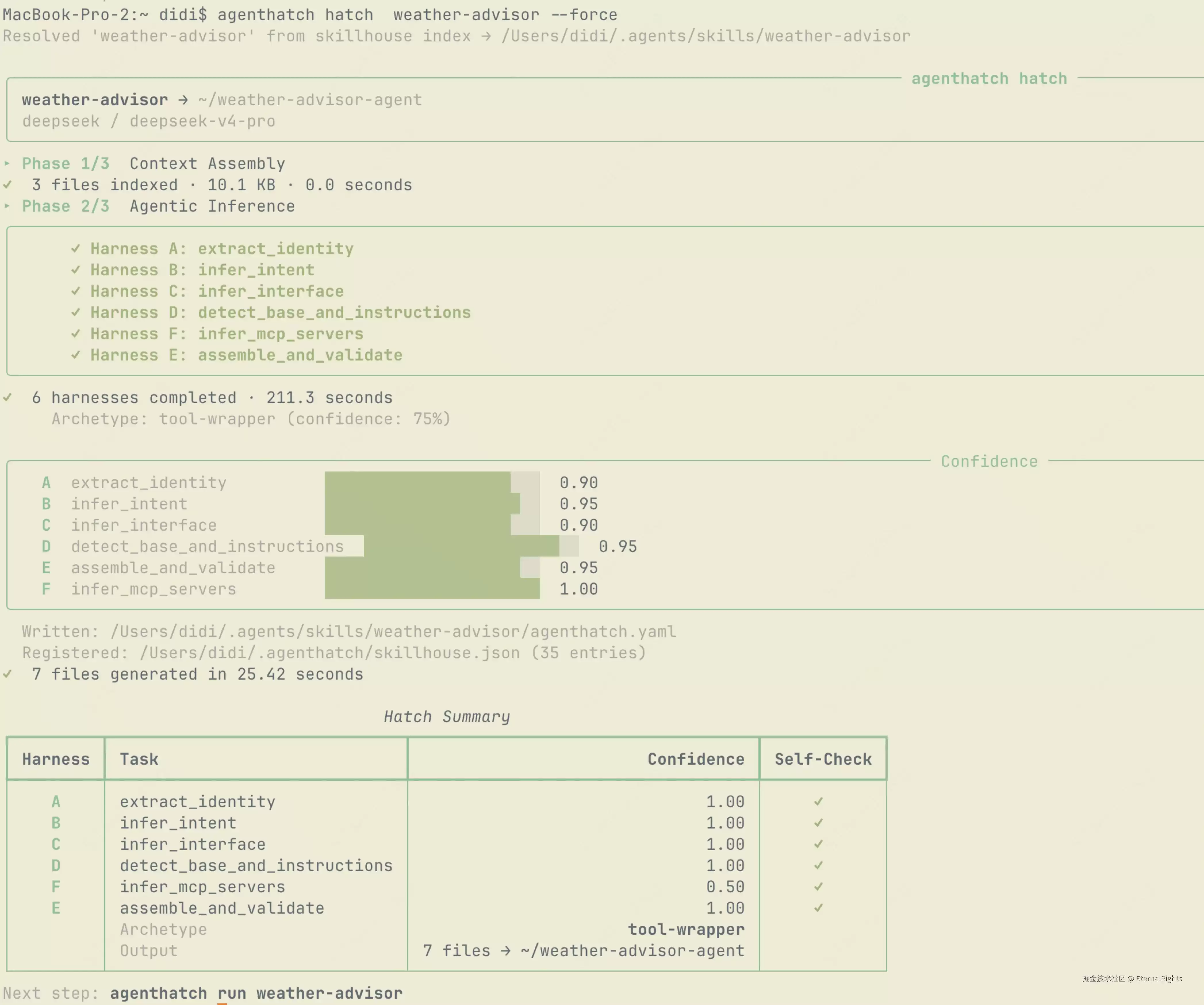 hatch 运行完成后,你将得到一个完整的 Python 包:
hatch 运行完成后,你将得到一个完整的 Python 包:
weather-advisor-agent/
├── pyproject.toml
├── runtime.toml
├── README.md
├── agenthatch.yaml
└── src/weather_advisor/
├── __init__.py
├── agent.py # 继承 AHCoreAgent,带 PlanLayer
├── tools.py # get_weather(city: str) -> WeatherResponse
└── references.py
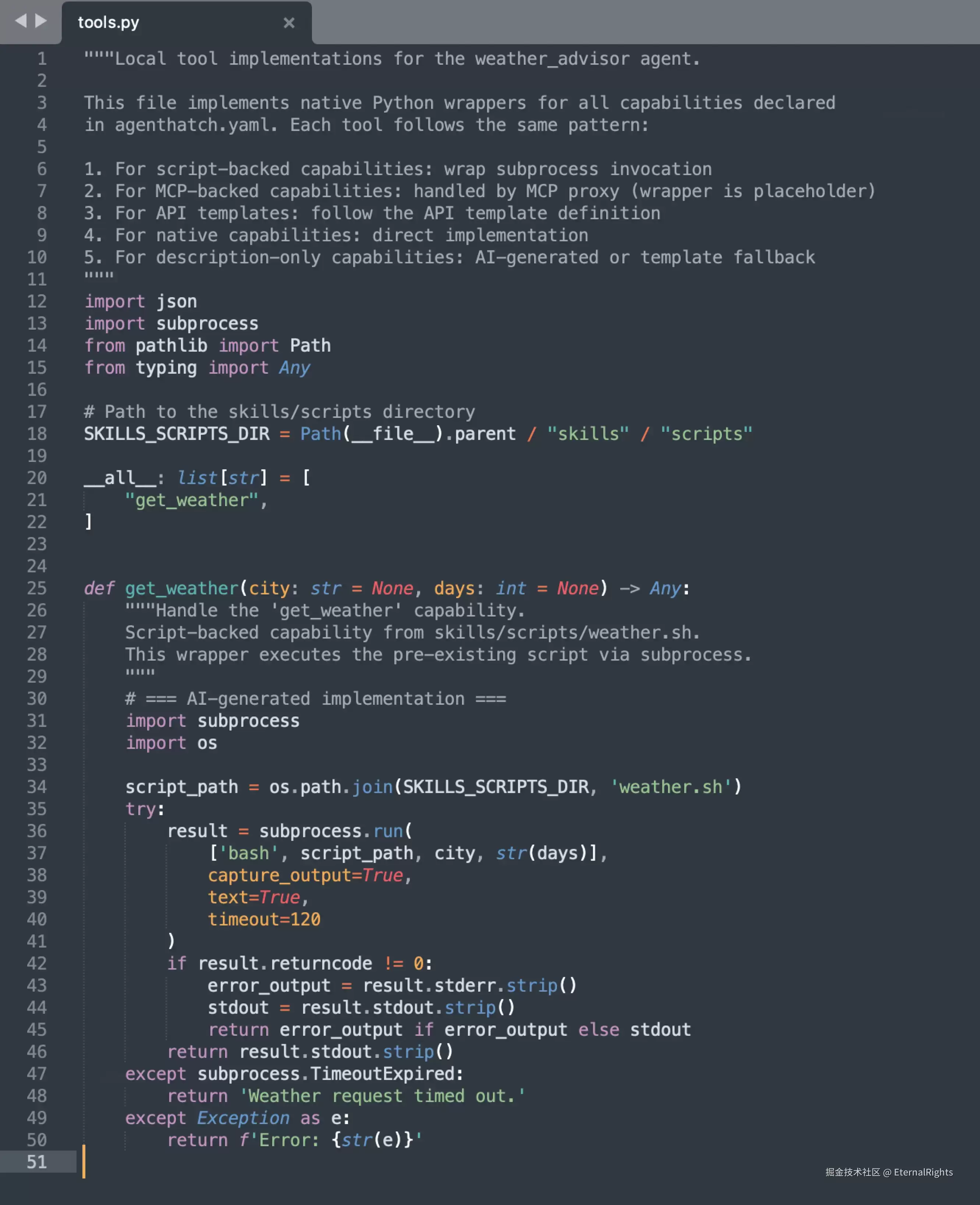
请注意tools.py——由 Harness C 推理得出的工具签名,是带有类型注解的 Python 函数,而不再是散文描述。get_weather(city: str) -> WeatherResponse,参数类型和返回类型都明确指定,LLM 无需再进行猜测。
Step 3:运行
agenthatch run weather-advisor
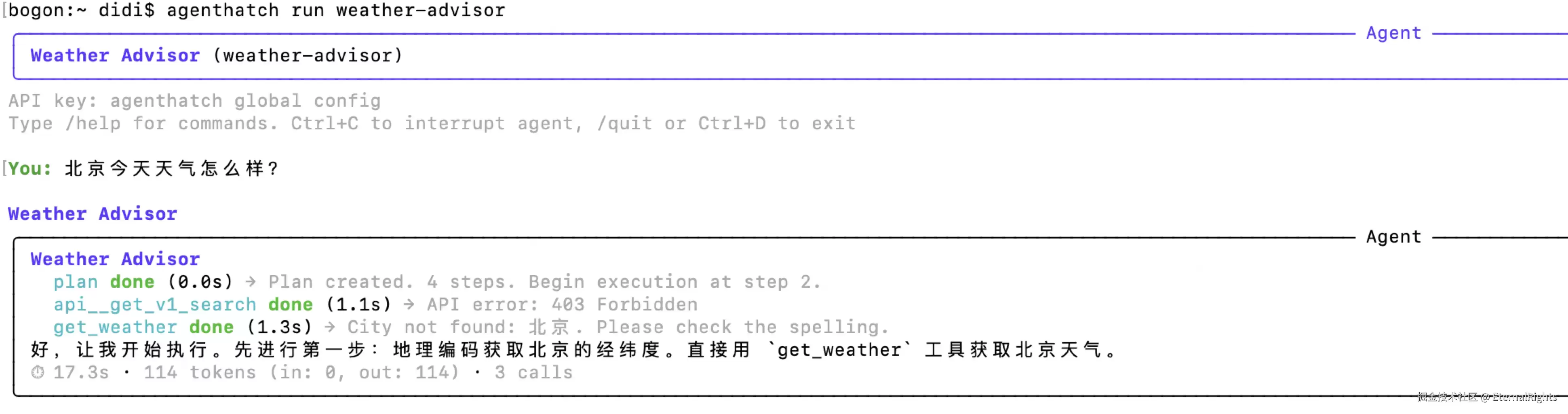
运行起来后,它是一个正式的交互式 agent,具备工具调用、上下文压缩以及 PlanLayer 驱动的执行能力。它不依赖 Claude Code,不依赖 Codex,也不依赖任何 host agent。它就是一个独立的 Python 程序。
六、SKILL.md vs agenthatch,一张表说清楚
| 对比项 | SKILL.md(裸的) | agenthatch(孵化后) |
|---|---|---|
| 执行方式 | LLM 在 runtime 解读 | 编译成独立 Python 包 |
| 隔离 | 所有 skill 共享一个 context | 每个 agent 有自己的运行时、工具、配置 |
| 校验 | 无,typo 和歧义 runtime 才爆 | 代码生成前 schema 校验 AHSSPEC |
| Token 成本 | 全文塞 system prompt,每轮都烧 | 约 150 字节运行时配置 |
| 工具定义 | 散文描述,LLM 猜怎么调 | 类型注解的 Python 函数 + JSON Schema |
| MCP | 每个 agent 手动接线 | 自动检测、自动配置 |
| 确定性 | LLM 每次解读都不一样 | 同一 SKILL.md → 同一 AHSSPEC 结构(低温推理) |
| 多 skill 扩展 | 3-5 个就开始衰减 | 无上限,每个 agent 独立进程 |
| 调试 | 读 LLM 的 chain-of-thought 祈祷 | 标准 Python 调试、日志、测试 |
七、踩坑记录(这玩意儿不完美,我直说)
技术文章不写踩坑经历就是耍流氓。下面我将 agenthatch 目前存在的所有问题都坦诚地列出来:
坑 1:Python only。 目前仅支持 Python。对 JS/TS 的支持正在开发中,但尚未发布。如果你使用的是 Node 生态,还需要再等一等。
坑 2:需要 LLM API key。 Phase 2 的六个 Harness 需要调用 LLM,可以使用 DeepSeek、OpenAI、Anthropic 等,但必须有 API key。想要完全离线?目前还不行。
坑 3:单文件 skill 支持。 多文件目录支持正在开发中。目前,一个 SKILL.md 带几个脚本文件是没有问题的,但更复杂的多文件 skill 目录还在打磨中。
坑 4:v0.9.x,很早期。 肯定存在 bug。我亲自运行的时候,Harness E 偶尔会出现 JSON 解析失败的情况,会回退到 raw chat 模式进行重试。代码里包含这个回退逻辑,但这意味着并非 100% 稳定。
坑 5:Windows 没测过。 我主要在 macOS 和 Linux 上运行,没有在 Windows 上进行过系统测试。路径处理方面可能存在问题。
坑 6:Harness 调用是串行的,不是真并行。 README 中写的是"6 harnesses working in parallel",但实际查看 engine.py 中 Orchestrator.run() 的实现,A→B→C→D→F→E 是按顺序分发的(D 依赖 C,E 依赖前面所有步骤)。我后来意识到 README 中的这个描述有些夸张,当前正在修改文档。先坦诚地告诉你。
八、适合谁?
- Claude Code / Codex CLI / OpenClaw 用户,skill 超过 3 个就感觉不对劲的——这是核心受众,你们体验最深
- 智能体开发工程师,希望将 skill 沉淀为可交付、可复用的 agent 产物,而不是每次都让 LLM 重新解读散文
- 团队 lead,希望为团队建立一套 skill → agent 的标准化产线,将 skill 作为源码管理,将 agent 作为制品管理
- 编译器/DSL 爱好者,想了解 LLM 如何被拆解为专业化流水线,用于编译前端的工作
不适合谁?
- 只有一两个 skill 的个人玩家——杀鸡用牛刀,Claude Code 原生功能已经够用
- 等待"完美工具"的人——这个工具目前并不完美,处于 v0.9.x 阶段,需要边飞行边修理
- 想"零代码搭 agent"的人——agenthatch 不是 no-code 平台,它是一个编译器,你需要会写 skill 并且能够阅读 Python
九、谁在做这个
我是 EternalRights,我的 GitHub 主页是 github.com/EternalRigh…。
此前,我为 pytest 提交过 8 个 PR,都是针对核心代码的真实 bug 修复,而不是简单的文档 typo;还为 agent-browser 提交过 1 个 PR。agenthatch 是我第一个从零到一独立完成的项目,所有代码都是在业余时间和周末一行一行敲出来的。
开源社区教给我最重要的一句话是:发布比完美更重要。 这个工具目前并不完美,但它已经能够运行,能够帮助到一些人。剩下的问题,我们边飞边修。
如果你也在使用 Claude Code 或 Codex CLI,并且当你管理的 skill 超过三个时就感觉不对劲,不妨试一试。
仓库地址
github.com/agenthatch/…
pip install agenthatch
有问题直接在评论区提出,不整虚的。如果你觉得这个思路有意思,可以给个 star,这对我继续努力下去非常重要。
最后,再次强调那个范式判断,因为它值得被记住:
你编写 skill,不是在编写 prompt,而是在编写 agent 的源码。而 agenthatch,正是它的编译器。这一理念,我相信终将被验证,时间会给出答案。