图解 MongoDB 01 - 文档数据库
许多入门教程简单将MongoDB描述为“用JSON存数据的数据库”,仅止于insertOne。实际上,它是一个由driver、mongod和存储引擎三层构成的系统,需要从架构层面理解。
掌握这三层“相同接口、不同职责”的划分,可以解答线上常见的疑问:比如相同查询在不同driver下表现差异明显,看似较小的集合写入却突然抖动,以及“文档模型更灵活”在数据治理时反而成为负担。这些疑惑无法仅从insertOne或find操作中找到答案,必须从架构层面入手。
先把机制边界说清楚
一条查询在MongoDB里并非由某个黑盒直接执行,而是依次经过driver协议层、mongod逻辑模型层,最终到达存储引擎的页、索引、事务与日志。
- driver层:负责将应用对象序列化为BSON,通过Wire Protocol发送给服务端,同时管理连接池、读偏好与重试。
- mongod层:处理网络与鉴权、查询解析与优化、集合与文档的逻辑模型、复制集与分片路由,以及事务调度。
- 存储引擎层:负责数据的实际存储。MongoDB默认采用WiredTiger,管理B‑tree页、Cache、journal、压缩和锁。
这三层架构类似于MySQL的Server层与存储引擎层之间的缝隙——但MongoDB将“应用协议”和“逻辑模型”拆得更清晰。后续讨论索引、复制、分片时,所有机制立足于mongod层;而涉及内存、持久化、压缩时,则全部下沉到WiredTiger。
整体路径
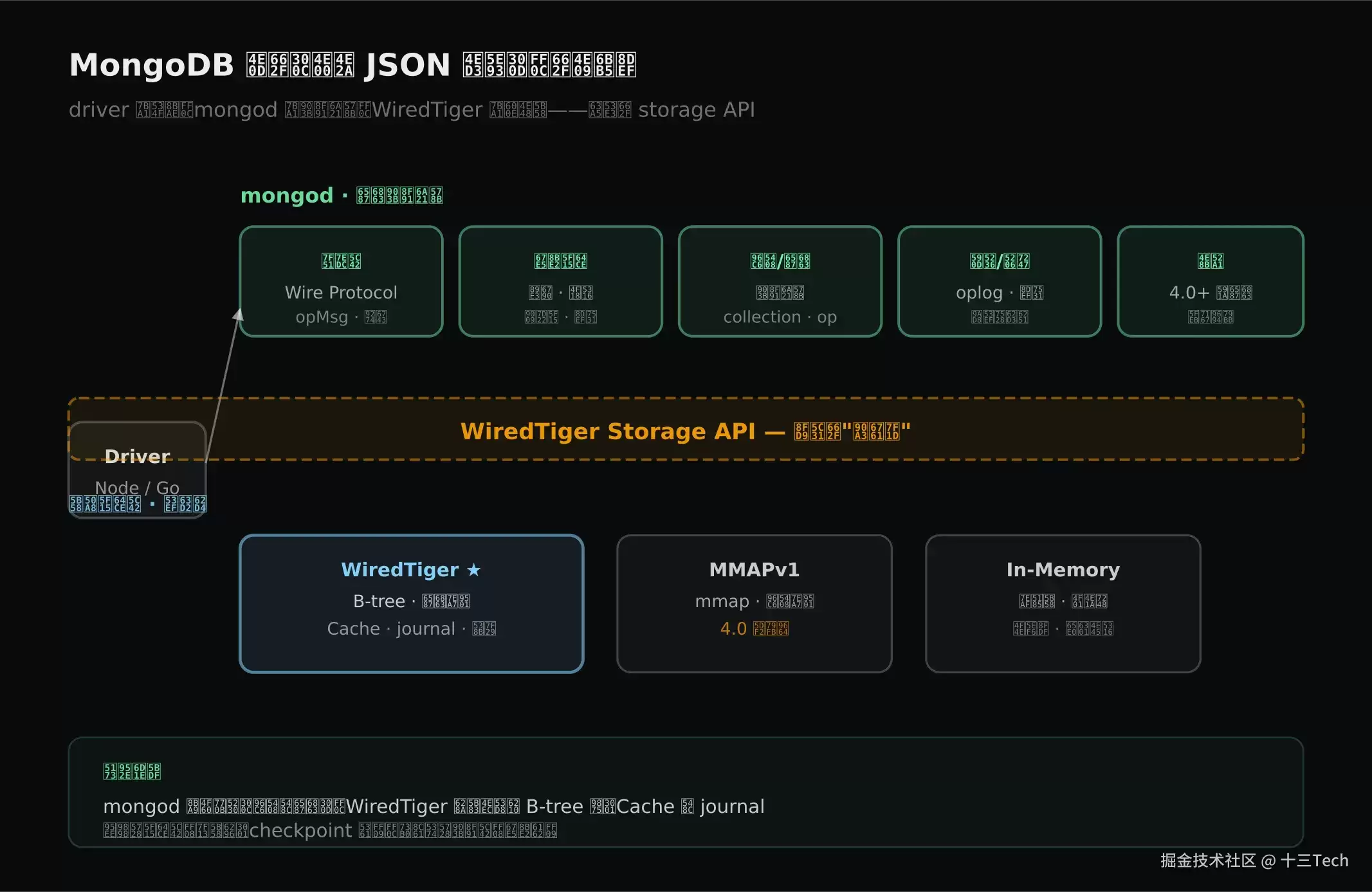
上图展示了入口与边界:宏观上,driver将操作序列化后发送给mongod,mongod解析、优化并调用存储引擎接口,WiredTiger访问B‑tree页和索引,最终将文档返回给上层。这套分层是后续所有MongoDB机制的总地图。
文档模型不是“JSON”,是BSON的逻辑投影
许多人将MongoDB的“灵活”归功于JSON,实际上JSON只是对外的展示形式。真正在driver、mongod、WiredTiger之间流动的是BSON——一种带类型标记的二进制格式。当同一个find返回给客户端时,driver才将BSON还原为语言对象。
这一差异能解释一个反直觉的现象:MongoDB宣传“无schema”,但文档在BSON层面是有类型的。_id是ObjectId、createdAt是64位时间戳、tags是数组——这些类型一旦确定,就不会像文本JSON那样模糊。
因此更准确的说法是:MongoDB是“schema可选”而非“schema不存在”。可以让每个文档字段都不同(多形性),也可以用JSON Schema做强约束(模式治理)。灵活与治理处于同一光谱的两端,选择取决于业务对一致性的容忍度。
文档模型 vs 关系模型:那条缝在哪里
将MongoDB与MySQL对比,区别不在“存JSON还是存表”,而在于建模单位不同:
- 关系模型以“行”为单位,通过外键和JOIN表达关联,强调规范化、无冗余。
- 文档模型以“文档”为单位,将关联对象内嵌在一起,强调局部完整、一次访问获取全部。
这两种建模取向决定了写入和读取的形状完全不同:
| 维度 | 关系模型 | 文档模型 |
|---|---|---|
| 建模单位 | 行(tuple) | 文档(BSON) |
| 关联表达 | 外键 + JOIN | 内嵌 + 少量引用 |
| 规范化 | 强,避免冗余 | 弱,容忍冗余 |
| 典型访问 | 多表 JOIN | 单文档读写 |
| 模式变更 | DDL,可能锁表 | 加字段即生效 |
文档模型最大的优势并非“灵活”,而是访问局部性:一个业务实体整体存为一个文档,应用读一次即可获取全部信息,无需JOIN。这一优势在内容、配置、订单详情、用户画像等“整体读、整体写”的场景中尤为明显。
代价同样清晰:当需要跨实体聚合、强一致关联时,文档模型要么依赖冗余承担一致性成本,要么通过$lookup退化为类似JOIN的操作,反而比关系模型更别扭。
取舍与边界
这套分层的短板在于问题会跨层传播,这一点与MySQL几乎一致:
- driver配置错:连接池过小导致查询排队,现象像是“MongoDB慢”,实际是客户端问题。
- 查询计划差:优化器选错索引,WiredTiger被迫扫描大量页,表现为CPU和延迟飙升。
- 存储引擎抖动:Cache不足或checkpoint未对齐,逻辑层看似正常,但P99抖动至几百毫秒。
版本演进上,MongoDB从4.0补齐多文档事务、4.2引入分片事务、5.0加入时间序列集合、7.x持续打磨column compression与queryable encryption。但driver / mongod / 存储引擎这套三层骨架始终未变。学习MongoDB的机制,本质就是沿着这三段路深入。
典型问题:用机制化例子排查
可用一个机制化例子理解:一条find文本看起来简单,但耗时可能来自driver序列化、mongod优化器选错索引、WiredTiger Cache未命中、锁等待或结果集过大。排查时先拆开链路,比直接怀疑“MongoDB慢”更可靠。
可以落实到以下动作:
- 排查慢查询时先分层:driver往返、查询计划、存储引擎访问、锁等待分开审视。
- 用
explain("executionStats")、mongostat、db.currentOp()和WiredTiger统计互相校准,不依赖单一现象下结论。 - 核心集合保持稳定的访问路径,避免一次发布同时改变查询、索引和连接池参数。
- 将mongod指标(opcounters、connections)和WiredTiger指标(cache、checkpoint)纳入监控,否则只能看到结果,看不到原因。
收束:先有地图,再谈优化
整个查询执行链路构成了理解MongoDB所有机制的总地图。先理清driver、mongod与存储引擎的分工,再深入索引、事务与分片,排障时才能避免在黑盒外绕圈。