多模态融合:是数据形态工程,不是 Prompt 工程
《Agent设计模式之美》感知模块最后一讲聚焦“多模态融合”,它直接判断:多模态融合不是prompt工程,而是数据形态工程。前三讲默认信息已是token,这一讲处理数据进入Agent前的形态决策。
这一讲的核心在于工程师需要判断每张图、每页PDF、每段日志该用什么形态进入Agent,而非模型供应商的职责。
一、图片没想象中那么贵
我曾本能认为“能转文本就转文本”,但这一讲提供了明确的token数学。

1024乘1024的图约1400 token,是同长度文本的1.5倍。真正昂贵的不是单张图,而是80页PDF整份塞进(超过15万token),以及Agent loop每一步重新打包同一张图。这两个成本陷阱可用PDF拆解和prompt caching解决,前提是先做token数学而非凭感觉。
二、老编辑的版面工艺
一位老练的财经编辑不会全做成纯文字:市场趋势用折线图,空间关系是信号;财务数据用表格,结构是信号;分析观点用文字,逻辑是信号。
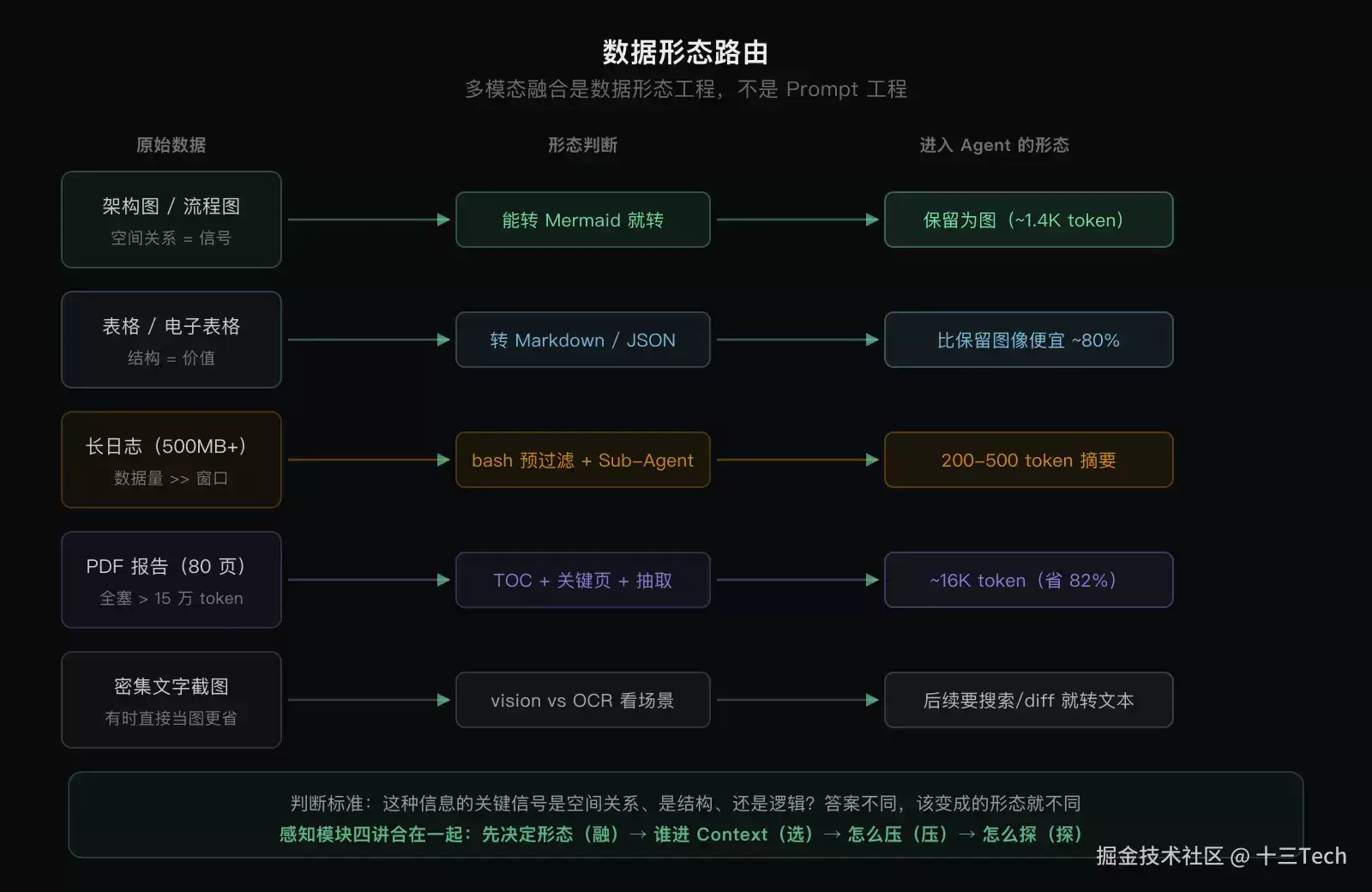
Agent工程师需借鉴这种版面工艺。架构图和流程图保留为图,空间关系本身就是信号。表格转markdown,结构是价值。长日志走bash预过滤再交给Sub-Agent,数据量远超窗口。判断标准很简单:这种信息的关键信号是空间关系、结构还是逻辑?答案不同,其应变的形态就不同。
三、金融研报 Agent 的完整 Pipeline
这一讲以一份80页行业研报作为具体例子。

MultiModalFuser将PDF拆分为TOC、关键页、关键图表、表格,丢弃装饰图,合计约16K token,对比直接喂80K节省82%。随后三个任务并行运行:核心论点摘要、数字事实核查、销售要点生成,成本从0.27降到0.27降到0.058。
三个关键工程决策:第一,关键图表识别靠业务关键词字典(如“市场规模”“市占率”“营收”“毛利率”),这是金融领域的信号资产;第二,装饰图必须丢弃,80页研报30到50张图里只有5到10张有信息量;第三,数字核查必须强制引用,每条数字带page或chart引用,找不到引用的confidence降级。这套CriticalChartSpec关键词不是普通配置,而是领域知识沉淀,与我做服务端时做“业务关键词字典”“领域规则引擎”完全同构——领域知识必须沉淀为显式的、可维护的结构化资产。
四、lazy import 工程纪律
Hermes Agent规定音频相关依赖必须lazy load,不能在module顶层直接import。原因很简单:Agent运行在各种环境,如本机、CI、Docker、远程SSH、WSL,很多环境没有音频设备也没有PortAudio。启动时硬import音频库,Agent可能在还没处理任何任务之前就崩溃。这和服务端做“可选依赖/插件机制/feature flag”是同一思路——保护主进程启动稳定性。pdfplumber、cv2、pydub、transformers这些多模态依赖,凡是80%用户不会用到且对运行环境有依赖的,都应该函数内lazy import或try-except优雅降级。
五、感知模块四讲收束
四讲合在一起切的是同一个问题:当下这个session里Agent怎么看清楚世界。
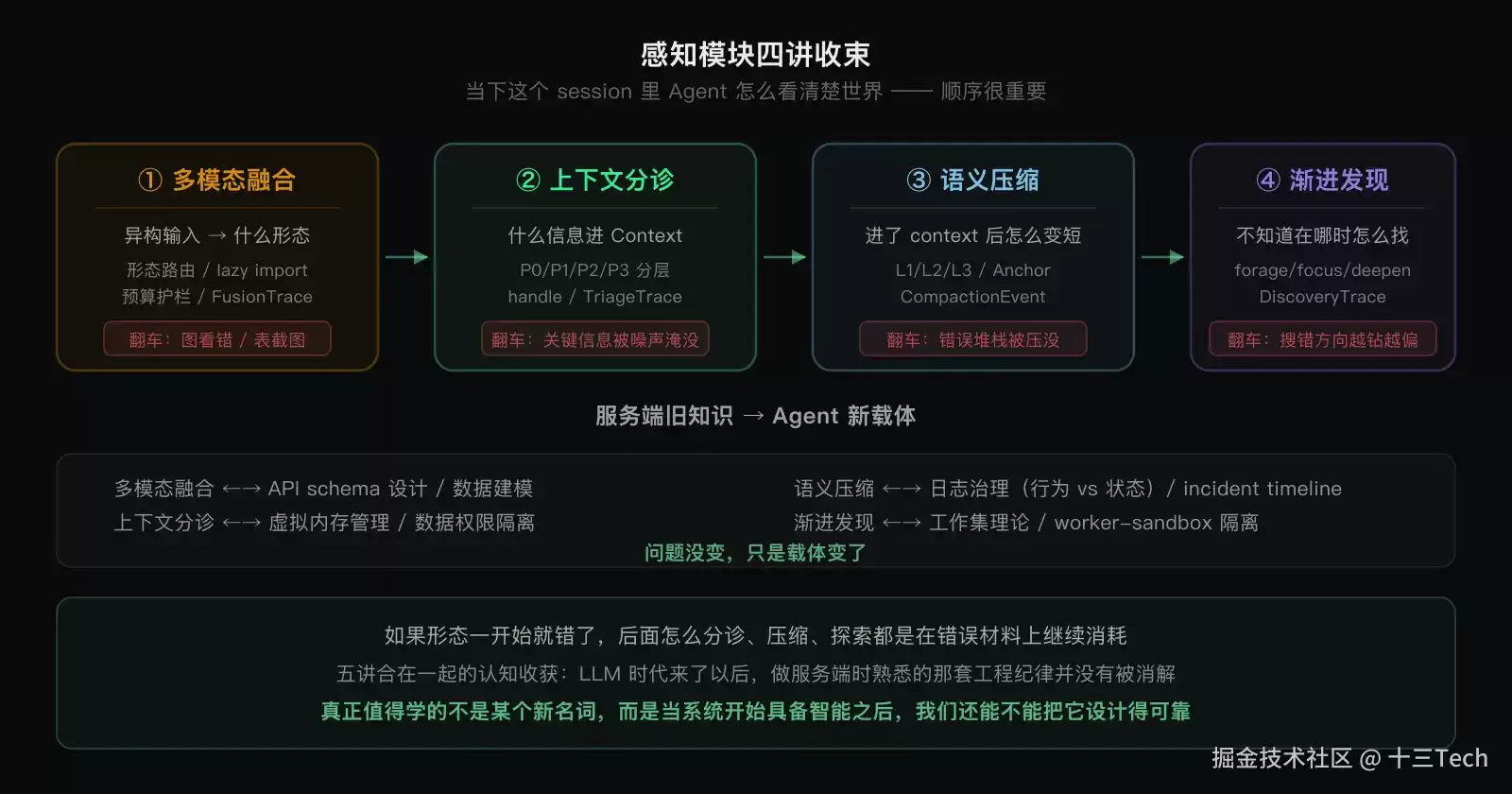
注意此处顺序是数据形态流水线的先后,而非这几讲的阅读顺序。多模态融合在流水线里最靠前,先决定数据该变成什么形态;分诊再决定哪些信息靠近模型;压缩负责长会话里的工作记忆;发现负责未知空间里的探索。如果形态一开始就错了,后面如何分诊、压缩、探索都是在错误材料上继续消耗。
这也是整个感知模块最大的认知收获:问题没变,只是载体变了。虚拟内存管理、工作集理论、日志治理的“行为 vs 状态”分离、主进程不做重活——这些老经验在Agent场景几乎可以平移。感知层不是新知识,而是老问题在新载体上的回归。