Meta卖算力:Palantir骂街:智谱成硅谷顶流 AI Capex的故事要换一个讲法
AI行情剧烈波动,市场聚焦于Meta计划将闲置算力出租的潜在举动。这一调整令投资者重新审视AI基础设施的真实需求与资本开支逻辑,引发广泛讨论。
若时间退回三年前,这则消息或许不会引发太多关注。云计算本质上是将服务器碎片化后转售的商业模式,亚马逊、微软、谷歌等巨头早已深耕于此。CoreWeave、Nebius等新兴云厂商也沿着同样路径,将英伟达芯片作为融资抵押物,不断撬动更多资本购置芯片。
然而,当主角换成Meta,事态便呈现出截然不同的意涵。
Meta过往对算力的理解并非如此。它购买芯片、建设数据中心、争夺电力和土地,目标是服务于自有模型、广告系统、推荐算法,以及首席执行官扎克伯格宣称日益临近的超级智能。它并非云服务商,原本不依赖出租设备盈利。
一家公司过去强调:我需要尽可能多的机器,因为未来会吞噬它们。如今它则表示:如果这些机器暂时闲置,也可以转售给他人。
这并不直接证明算力过剩,但这一信号绝不能轻率放过。
股市暴跌当日,Palantir首席执行官Alex Karp在CNBC访谈节目中,进行了长达近二十分钟的激烈批评。
他原计划讨论Palantir与英伟达的新合作,却迅速将话题转向OpenAI和Anthropic的token收费模式。他透露,多位首席执行官私下抱怨当前企业AI采用状况:为不创造任何价值的token买单,同时必须交出自身数据。他甚至将日益昂贵的模型账单,形容为加诸企业身上的财富税。

过去两年间,业界讨论焦点是谁敢于支出、谁支出更快、谁能率先建成数据中心。如今,问题已悄然转变。机器采购完成后,谁能持续让它们满负荷运行。
Meta的计划尚未正式落地为一项业务。据公开报道,其内部存在一个名为Meta Compute的方向,可能出售原始算力,或仿效亚马逊Bedrock模式,将不同模型置于自身基础设施上销售给开发者。扎克伯格此前在股东会上提及,外部公司几乎每周都会询问,能否购买其API服务或部分计算资源,并愿意支付高于Meta成本的价格。
当时他也补充道,公司尚未采取行动,因为Meta自认为仍需使用这些算力。
若算力能够被充分利用,出租是一项可选项。若算力无法被充分利用,出租则成为资产负债表的镇痛剂。
最难以判断之处也正在于此。Meta可能只是在建设节奏中腾出一个窗口期,将暂时闲置的资源对外出售。它也可能是在向投资者传达,千亿美元级别的AI支出无法一直依赖远方的超级智能来支撑,必须首先找到一条更接近现实的收入线。
这两种解释皆有其合理性。
需求没有消失,只是开始挑人
Capex是AI叙事的核心要素,其地位无可替代。与2021年的流动性泛滥类似,Capex增长预期是市场炒作的根基:预期持续增长、流动性持续注入,所有分支领域才能同步上涨。看到Meta准备出售算力,许多人第一反应是AI Capex即将崩塌,大公司终于承认采购过多,半导体的盛宴该收场了。
这一结论过于简化。
公开数据尚不支持如此干脆的判断。AWS一季度收入增长28%,达到376亿美元,创下近年罕见的高增速。Google Cloud一季度增速更为强劲,收入达到200亿美元。微软Azure仍维持在约40%的增速水平。
亚马逊仍表示今年资本支出可能达到2000亿美元。Alphabet将2026年资本支出指引提升至1800亿至1900亿美元。Meta自身也将全年资本支出提升至1250亿至1450亿美元。
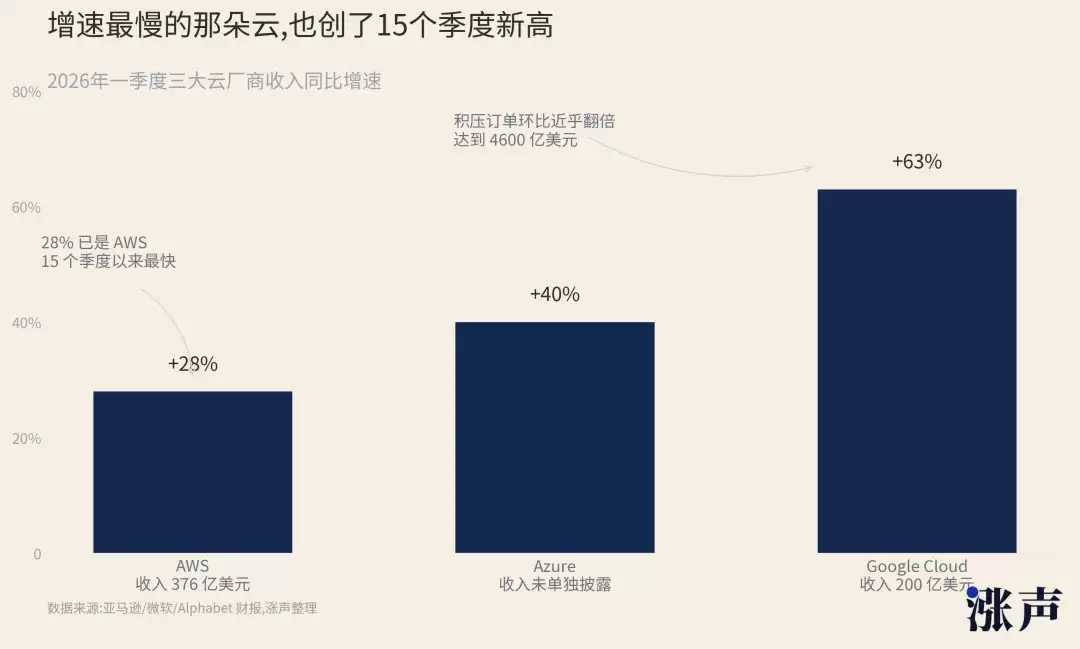
这些数据并不指向一场需求崩塌。
更准确的描述是一场分流。
云服务商的处境与模型厂商截然不同。云服务商出售的是通路。只要道路上有人通行,无论车辆由谁制造,它们都能收取费用。OpenAI、Anthropic、企业客户、政府客户、创业公司,最终都需要落脚于某片数据中心、某种芯片、某条网络和某个电力合同之上。
因此,三大云服务商能够继续保持强势。
AWS甚至在6月底上调了一项AI云服务的价格。这项服务允许客户提前锁定GPU,AWS将该服务7月后的价格提高了约20%。1月时已调整过一次,幅度约为15%。这并非需求疲软时会出现的举措。
稀缺状态下,卖方会选择涨价。
但模型公司未必都能如此从容。
模型公司的资产需要更挑剔的运营。算力并非放置在那里就能产生收入。它需要被更智能的模型、更高频的用户、更昂贵的企业工作流持续填充。只有当模型足够优秀时,用户才愿意忍受排队、限额、涨价以及日益复杂的订阅层级。
这也是为何Anthropic被市场视为另一种类型的公司。它并非因为价格低廉,而是因为用户愿意将高价值的任务交付给它。编写代码、修改系统、运行长任务、对接企业工作流,这些任务一旦真正进入生产环境,其消耗的token将远超闲聊场景。
强模型面临的麻烦是机器不够用。
弱模型面临的麻烦是机器无人珍惜。
这两种麻烦都涉及算力,但它们并非同一事物。
xAI那条路径也透露出类似味道。Grok尚未像最强模型那样形成清晰的企业认知,但马斯克体系中的一部分算力却可以流向Anthropic。这一动作比任何口号都更冷静。机器不认识创始人,它只认识谁能将其满负荷运转。
Google与Meta的关系也表明事情远非表面那般简单。6月有消息称,Google限制了Meta对Gemini的使用,原因是Meta希望购买的算力超出了Google能提供的范围,甚至影响了Meta内部部分AI项目。一家公司一边考虑出售算力,另一边却在某些任务上难以购买到足够的头部模型能力。
这并非传统意义上的过剩。
这是错配现象。因为账单开始变得刺眼。
云服务商可以继续涨价,因为它们出售的是确定性。客户需要的是一段时间内必定能获得的GPU、一片稳定的数据中心、一套不会在半夜中断的基础设施。
但企业客户获得算力后,问题并未终结。
它们还需要将这张账单交给首席财务官。CFO不会询问你使用了多少token,他会追问这些token为公司节省了多少成本、增加了多少收益、减少了多少错误。
到了企业那里,token变成了电表
这就回到了开头提及的Karp那场访谈。
他将许多AI公司向企业推销的东西定性为过度销售。上节目前一天,Palantir还在X平台发布了一份九点声明,阐述所谓AI主权,其中专门指出了tokenmaxxing这种模式。这个词难以直译,字面意义不算好听,但意思并不复杂:将消耗token视为进步,将烧钱视为使用,将账单视为生产力。
Karp将OpenAI、Anthropic这类前沿实验室推到了讨论前台。他的意思并非企业不该使用最强模型,而是企业不应将自己的数据、流程和业务判断全部交出,然后按消耗量支付一张不断膨胀的账单。
Palantir希望出售的是另一种东西。并非一个通用聊天框,并非单一API,而是将数据、审批、权限、运营规则和AI整合进同一套业务系统。客户花钱购买的并非使用了多少次AI,而是某条生产线、某套风控流程、某个政府任务是否真正得到了改造。
企业中真正负责财务决策的人已经开始觉醒。
UBS近期与企业IT高管交流后,得出一个清晰方向。许多企业并非不再使用AI,而是在为AI支出设置刹车。约60%的受访企业正在压缩token开支、增加使用护栏,尤其是那些已经度过试用期、开始将AI融入日常流程的企业。
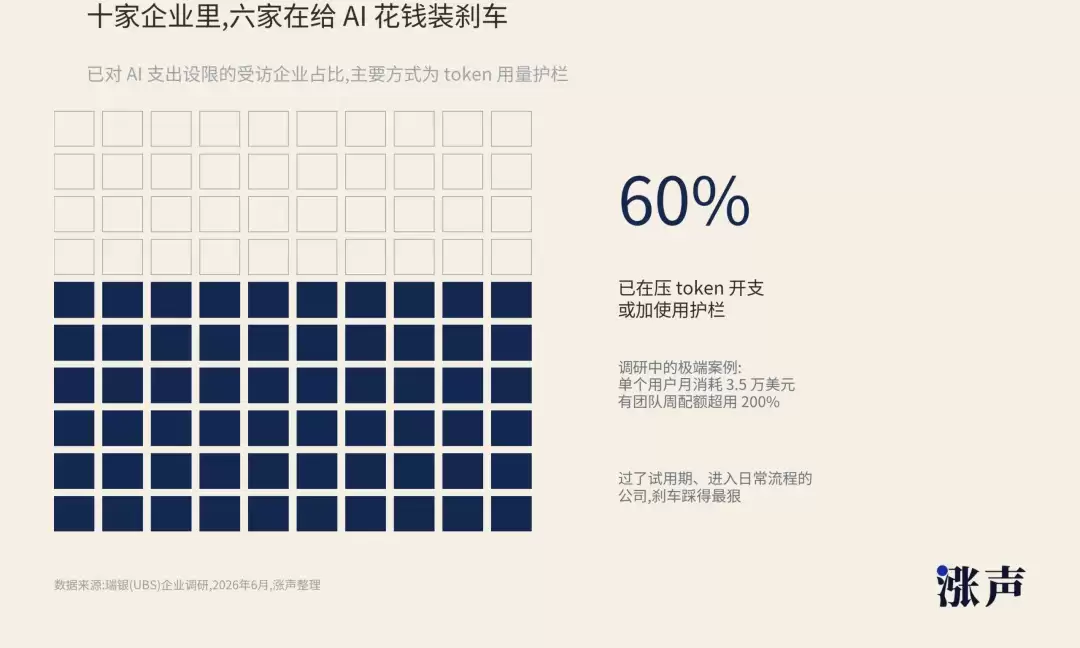
这也构成了一个有趣的反转。
AI从玩具变为工具后,花钱反而变得更难。在玩具阶段,老板愿意给予预算,因为大家都害怕错过机会。在工具阶段,CFO会追问它替谁节省了工时、替谁增加了销量、替谁降低了风险。
在这张表上,token不像收入。
它更像电表。
你当然可以说,电表转得快表明工厂在运营。也可以说,电表转得太快而产量没有提升,说明这台机器存在问题。
AI agent将这个问题进一步放大。OpenAI与几所大学合作的一项Codex研究中包含一组令人震撼的数据。2026年上半年,Codex活跃用户增长超过五倍;OpenAI内部部分岗位的输出token也暴涨,法律岗位的中位数月输出token较2025年11月高出13倍,研究岗位高出50多倍。
另一项研究将问题阐述得更直接。agentic coding任务消耗的token,可以比普通代码聊天和代码推理高出1000倍。同一任务在不同运行之间的token消耗可能相差30倍。
这才是当前算力紧缺的深层原因。
并非大家多问了几句聊天机器人。
是软件开始演变为一群会反复读取文件、运行命令、修改代码、遭遇失败、重新尝试、再次失败、再次尝试的微型工人。它们没有午餐时间,但每一步都在消耗token。
当token变成电表,谁拥有发电厂,谁就掌握权力。但谁浪费电力,谁也将首先受到审查。
账单一变厚,便宜模型就有了位置
CFO一旦开始关注这张电表,下一步几乎无需他人指导。
他会询问,哪些任务必须使用最强模型,哪些任务只需使用够用的模型。
此时,GLM、Kimi、DeepSeek、Qwen这些开源模型就不再仅仅是技术新闻。它们转变为企业采购桌上的砍价工具。
连硅谷顶级风投机构a16z的马克·安德森都表示,许多AI从业者已将智谱GLM-5.2视为首批能够在多数任务中匹配甚至超过美国头部公开模型的中国模型。这一判断未必是最终结论,但它让企业多了一个谈判筹码。
Coinbase提供了更具体的例证。Brian Armstrong表示,公司将默认AI模型切换至GLM 5.2、Kimi 2.7这类开源模型,再配合模型路由、缓存和精简上下文,Token使用量仍在指数级增长,但AI支出却削减了近一半。
这句话的核心杀伤力在于,企业首次可以将模型能力拆分采购。
最难的任务,继续交给最贵的模型。普通摘要、客服、信息抽取、模板化代码、内部知识库问答,则交给便宜模型和本地部署。
开源模型未必需要赢得全部战场。
它只需让采购部门相信,不是每一度电都要按豪宅电价付费。
到了这里,Meta出售算力就不再是一条孤立的新闻。
它与Palantir批评token、Coinbase切换开源模型指向的是同一件事:AI的支出链条开始被拆解。上游出售确定性,中游出售结果,下游压低单价。每一层仍在增长,但每一层都开始被追问,钱究竟花得值不值。
最难的不是买机器,是让机器一直有活干
过去两年,AI行业最容易讲述的故事是资源不足。
GPU不足,电力不足,数据中心不足,工程师不足,能将模型跑起来的云也不足。这个故事太过顺畅。只要东西不够,所有人都会本能地向前冲。先占据位置,先签署电力合同,先购买芯片,先将机器架设起来。
在抢夺资源时,人们不太会计算精细账目。
因为慢一步的代价看起来更大。
但Meta这条消息将另一个问题推到了前台。机器采购回来后,不会因为它价格昂贵就自动成为好生意。它需要每天有任务可做,需要有客户愿意付费,需要有模型将其满负荷运转,需要有应用将成本转化为收入。
这就是利用率。
利用率这个词听起来很冰冷,实则很残酷。它询问的并非你是否有未来,而是你今天这台机器是否在开工。它不关心你在发布会上如何表述,也不关心你购买的是否是最贵的GPU。它只关注一件事:这笔钱是否转化成了持续的现金流。
云服务商回答这一问题相对容易。它们本身就在销售基础设施。AWS、Google Cloud、Azure出售的是通路、电力和机房。客户需要训练模型、运行推理、托管应用,最终都必须落脚于某片云上。
因此,它们能够继续保持强势。
强模型公司也有自己的答案。如果模型足够强大,用户愿意排队,企业愿意接入,开发者愿意围绕它改变工作流,那么算力就不是库存,而是瓶颈。机器越多,它越能施展开来。
最难的是中间那一层。
它们有机器,有故事,有模型团队,也有庞大的预算。但是模型未能跑到最前沿,产品未能成为日常习惯,开发者也不愿为其改变工作流。对这类公司而言,算力从武器变为库存,只需要一次模型发布失败,或一次用户迁移。
库存未必无用。
但库存必须降价,必须出租,必须寻找新用途。
这就是Meta出售算力令人关注的原因。它不证明Meta失败,也不证明AI需求消失。它只是让市场首次看到,AI基础设施也会面临普通工厂遇到的问题。
工厂建好了,订单在哪里。
算力没有消失,只是开始分层
因此,对这件事的最佳理解,并非算力过剩。
这个词过于粗糙。
更精确的说法是,算力开始分层。
最上面那一层,仍然紧张。最强模型、最好的云、最稳定的GPU集群,仍然有人争抢。AWS的服务能够涨价,正是因为确定性本身具有价值。客户不仅仅购买GPU,它购买的是某一天、某一小时、某一批机器必定能用。
中间那一层,开始陷入尴尬境地。它或许并不差,但不够稀缺。它能运行模型,能进行推理,也能出售给外部客户。只是客户会比较、会砍价、会询问为何不用更便宜的模型,为何不用别人的云,为何这批机器一定值这个价格。
最下面那一层,会被开源模型和成本优化逐步挤压。企业不会为了普通任务永远调用最贵模型。它们会进行路由,会进行缓存,会压缩上下文,会将模型拆分为不同档次。
需求已经长大了。
小孩子花钱不看账单,成年人会看。AI进入企业后,也会经历这一过程。试点阶段,大家害怕错过机会;规模化阶段,大家开始计算账目。
计算账目之后,产业链就不会再像早期那样整齐划一。
有人继续涨价,因为他出售的是不可替代的确定性。有人转而销售结果,因为客户不愿为消耗本身付费。有人被迫降价,因为够用的替代品已经出现。有人将机器出租,因为机器闲置比低价出租更难看。
这几件事同时发生,就会让行业看起来充满矛盾。
一边是算力紧缺。
一边是算力出租。
一边是token消耗暴涨。
一边是企业压低AI支出。
一边是头部模型越来越强。
一边是开源模型越来越便宜。
它们并不冲突。它们只是表明,AI已经从总量故事,进入结构故事。
旧铁路的故事还会再讲一遍
十九世纪的铁路泡沫中,铁路本身并非虚假。
铁轨铺设下去,货物确实会运输,城市确实会成长,时间确实会被缩短。许多后来最有价值的商业网络,确实生长在那些铁轨旁边。
但这并不妨碍当年许多铁路修建者亏损。
他们输的并非方向。他们输在修建得太早、修建得太多、修建到了没有客货流的地方,或者借了太贵的钱去修建一条太慢才能回本的路。
互联网泡沫中的光纤也是如此。光纤本身没有错。后来整个世界都被它托举起来。错的是那一批账本,它们将未来几十年的需求一次性塞进了几年的资本支出里。
AI数据中心可能也会留下许多有用的东西。GPU会折旧,电力合同会续签,数据中心会更换设备,软件会越来越懂得消耗算力。今天看起来夸张的token消耗,几年后或许会像高清视频流量一样普通。
但资产有其自身的脾气。
它不关心你是否相信未来。它只关心每天是否有人来使用。
Meta出售算力的信号,正卡在这个位置。
它并非AI的终点。也并非半导体的终点。它更像是资本支出叙事行进到中段时,第一次有人打开门,让外面的人看到仓库里有多少机器。
有些机器会被头部模型消耗掉。
有些机器会被云客户租走。
有些机器会在价格战中变得便宜。
还有些机器,会静静等待一个尚未出现的应用。
过去两年,市场愿意相信所有机器最终都会等到自己的使命。现在它开始询问,谁先等到,谁等不到,谁等到了也赚不到足够的钱。
这个问题一经提出,AI的故事就发生了转变。
它不再仅仅属于那些购买机器最快的人。
它属于那些能让机器持续运转下去的人。