高可用 kubernetes 集群部署实操
Kubernetes(k8s)凭借卓越架构与灵活扩展成为容器编排标准,众多企业将核心服务迁移其上。如何通过RKE部署高可用集群,是本文探讨的主题。
前言
基础设施的可用性至关重要,各大云厂商已推出高可用k8s托管服务,如Amazon EKS、Azure Kubernetes Service、Google Kubernetes Engine等。
尽管托管服务众多,许多企业仍有自建集群的需求,从而催生了一批出色的k8s部署方案,其特点对比如下。
| 部署方案 | 特点 |
|---|---|
| Kubeadm | 1. 官方出品的部署工具,提供了k8s集群生命周期管理的领域知识。 2. 旨在成为更高级别工具的可组合构建块。 |
| Kubespray | 1. 支持在裸机和AWS、GCE、Azure等众多云平台上部署k8s。 2. 基于Ansible Playbook定义k8s集群部署任务。 3. 支持大部分流行的Linux发行版。 |
| Kops | 1. 仅支持在AWS、GCE等少数云平台上部署k8s。 2. 建立在状态同步模型上,用于dry-run和自动幂等性。 3. 能够自动生成Terraform配置。 |
| Rancher Kubernetes Engine(RKE) | 1. 著名的开源企业级容器管理平台Rancher提供的轻量级k8s安装工具。 2. 支持在裸机、虚拟机、公有云上部署和管理k8s集群。 |
上述方案中,RKE在易用性和灵活性上优势明显。以下将介绍如何通过RKE部署一套高可用k8s集群,文中使用的RKE版本为v0.2.2。
高可用k8s集群架构
首先需要了解高可用k8s集群的架构特点,下图是官方推荐的高可用集群架构图。
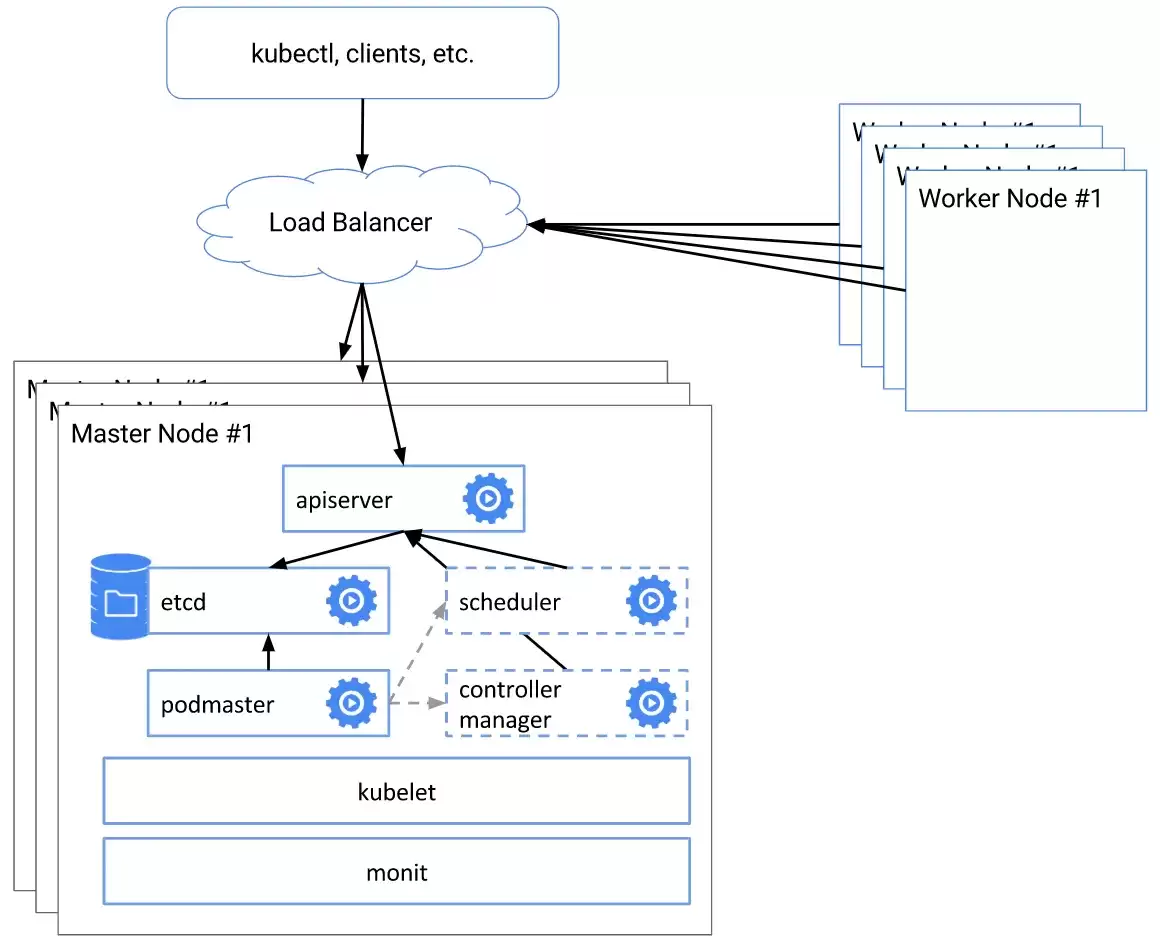
其核心思想是让k8s master节点中的各类组件具备高可用性,消除单点故障。
kube-apiserver对外暴露了k8s API,是整个集群的访问入口。由于apiserver本身无状态,可以通过启动多个实例并结合负载均衡器实现高可用。
etcd用于存储k8s集群的网络配置和对象的状态信息,是整个集群的数据中心。可以通过启动奇数个etcd实例建立一个冗余的、可靠的数据存储层。
kube-scheduler为新创建的pod选择一个供他们运行的节点。一个集群只能有一个活跃的kube-scheduler实例,可以同时启动多个kube-scheduler并利用领导者选举功能实现高可用。
kube-controller-manager是集群内部的管理控制中心。一个集群只能有一个活跃的kube-controller-manager实例,可以同时启动多个kube-controller-manager并利用领导者选举功能实现高可用。
此外,构建集群时还需要注意下列问题。
节点上k8s进程的可靠性。需要让kubelet、kube-scheduler、kube-controller-manager等进程在出现故障后能自动重启。为worker node中的非pod进程预留资源,防止他们将与pod争夺资源导致节点资源短缺。
使用RKE构建高可用k8s集群
节点规划
构建集群的第一步是将拥有的服务器按节点功能进行划分,下表展示了笔者环境下的节点规划情况。
| IP | 角色 |
|---|---|
| 192.168.0.10 | 部署节点 |
| 192.168.0.11 | k8s master - api-server, etcd, scheduler, controller-manager |
| 192.168.0.12 | k8s master - api-server, etcd, scheduler, controller-manager |
| 192.168.0.13 | k8s master - api-server, etcd, scheduler, controller-manager |
| 192.168.0.14 | k8s worker - kubelet, kube-proxy |
| 192.168.0.15 | k8s worker - kubelet, kube-proxy |
| 192.168.0.16 | k8s worker - kubelet, kube-proxy |
| 192.168.0.17 | k8s worker - kubelet, kube-proxy |
规划说明:
- 单独选择一台机器
192.168.0.10作为部署节点。如果机器数不多,可以将部署节点加入到k8s集群中。 - 为了保证可用性,选择三台机器部署k8s master组件。如果有条件,可以将etcd和master中的其他组件分开部署,这样可以根据需要更灵活地控制实例个数。例如,在访问压力不大但对数据可靠性要求比较高的情况下,可以专门选择5台机器部署etcd,另外选择3台机器部署master中的其他组件。
- 剩余四台机器作为k8s worker节点。节点个数需要根据实际情况动态调整。当有pod因资源不足一直处于pending状态时,可以对worker进行扩容。当node的资源利用率较低时,且此node上存在的pod都能被重新调度到其他node上运行时,可以对worker进行缩容。
环境准备
在完成节点规划后,需要进行环境准备工作,主要包含以下内容:
- 安装RKE:需要在部署节点(192.168.0.10)上安装RKE二进制包,具体安装方法可参考download-the-rke-binary。
- 配置SSH免密登录:由于RKE通过SSH tunnel安装部署k8s集群,需要配置RKE所在节点到k8s各节点的SSH免密登录。如果RKE所在节点也需要加入到k8s集群中,需要配置到本机的SSH免密登录。
- 安装docker:由于RKE通过docker镜像
rancher/hyperkube启动k8s组件,因此需要在k8s集群的各个节点(192.168.0.11 ~ 192.168.0.17这7台机器)上安装docker。 - 关闭swap:k8s 1.8开始要求关闭系统的swap,如果不关闭,默认配置下kubelet将无法启动。这里需要关闭所有k8s worker节点的swap。
配置cluster.yml
在完成环境准备后,需要通过cluster.yml描述集群的组成和k8s的部署方式。
配置集群组成
配置文件cluster.yml中的nodes配置项用于描述集群的组成。根据节点规划,对于k8s master节点,指定其角色为controlplane和etcd。对于k8s worker节点,指定其角色为worker。
nodes:
- address: 192.168.0.1
user: admin
role:
- controlplane
- etcd
...
- address: 192.168.0.7
user: admin
role:
- worker设置资源预留
K8s的worker node除了运行pod类进程外,还会运行很多其他的重要进程,包括k8s管理进程(如kubelet、dockerd)以及系统进程(如systemd)。这些进程对整个集群的稳定性至关重要,因此需要为他们专门预留一定的资源。
笔者环境中的worker设置如下:
节点拥有32核CPU,64Gi内存和100Gi存储。为k8s管理进程预留了1核CPU,2Gi内存和1Gi存储。为系统进程预留了1核CPU,1Gi内存和1Gi存储。为内存资源设置了500Mi的驱逐阈值,为磁盘资源设置了10%的驱逐阈值。
在此场景下,节点可分配的CPU资源是29核,可分配的内存资源是60.5Gi,可分配的磁盘资源是88Gi。对于不可压缩资源,当pod的内存使用总量超过60.5Gi或者磁盘使用总量超过88Gi时,QoS较低的pod将被优先驱逐。对于可压缩资源,如果节点上的所有进程都尽可能多的使用CPU,则pod类进程加起来不会使用超过29核的CPU资源。
上述资源预留设置在cluster.yml中具体形式如下。
services:
kubelet:
extra_args:
cgroups-per-qos: True
cgroup-driver: cgroupfs
kube-reserved: cpu=1,memory=2Gi,ephemeral-storage=1Gi
kube-reserved-cgroup: /runtime.service
system-reserved: cpu=1,memory=1Gi,ephemeral-storage=1Gi
system-reserved-cgroup: /system.slice
enforce-node-allocatable: pods,kube-reserved,system-reserved
eviction-hard: memory.available<500Mi,nodefs.available<10%关于资源预留更详细的内容可参考文章Reserve Compute Resources for System Daemons。
部署k8s集群
当cluster.yml文件配置完成后,可以通过命令rke up完成集群的部署任务。下图展示了通过RKE部署的k8s集群架构图。
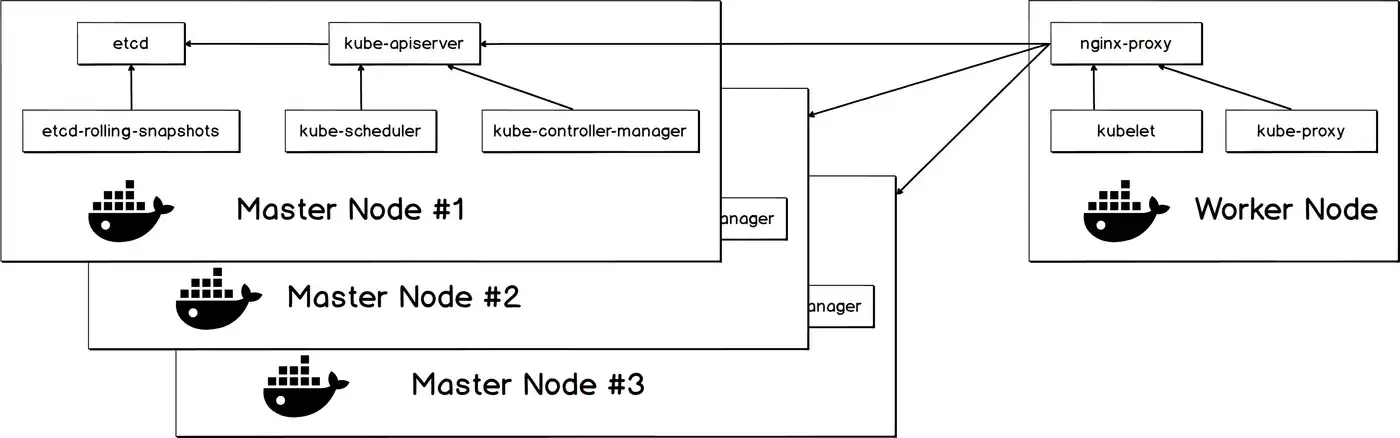
该架构有如下特点:
- 集群中的各个组件均通过容器方式启动,并且设置重启策略为
always。这样当他们出现故障意外退出后,能被自动拉起。 - Master节点上的kube-scheduler、kube-controller-manager直接和本机的API server通信。Worker节点上的nginx-proxy拥有API server的地址列表,负责代理kubelet、kube-proxy发往API server的请求。
- 为了让集群具有灾备能力,master节点上的etcd-rolling-snapshots会定期保存etcd的快照至本地目录
/opt/rke/etcd-snapshots中。
配置负载均衡器
在完成集群部署后,可以通过API server访问k8s。由于环境中启动了多个kube-apiserver实例以实现高可用,需要为这些实例架设一个负载均衡器。这里在192.168.0.10上部署了一台nginx实现了负载均衡的功能,nginx.conf的具体配置如下。
...
stream {
upstream apiserver {
server 192.168.0.11:6443 weight=5 max_fails=3 fail_timeout=60s;
server 192.168.0.12:6443 weight=5 max_fails=3 fail_timeout=60s;
server 192.168.0.13:6443 weight=5 max_fails=3 fail_timeout=60s;
}
server {
listen 6443;
proxy_connect_timeout 1s;
proxy_timeout 10s;
proxy_pass apiserver;
}
}
...这时,通过负载均衡器提供的端口访问API server会出现异常Unable to connect to the server: x509: certificate is valid for xxx, not 192.168.0.10。这里需要将负载均衡器的IP地址或域名加入到API server的PKI证书中,可以通过cluster.yml中的authentication配置项完成此功能。
authentication:
strategy: x509
sans:
- "192.168.0.10"修改完cluster.yml后,运行命令rke cert-rotate。
验证
在完成上述所有步骤后,可以通过命令kubectl get nodes查看节点状态。如果所有节点的状态均为Ready,则表示集群部署成功。
NAME STATUS ROLES AGE VERSION
192.168.0.11 Ready controlplane,etcd 1d v1.13.5
192.168.0.12 Ready controlplane,etcd 1d v1.13.5
192.168.0.13 Ready controlplane,etcd 1d v1.13.5
192.168.0.14 Ready worker 1d v1.13.5
192.168.0.15 Ready worker 1d v1.13.5
192.168.0.16 Ready worker 1d v1.13.5
192.168.0.17 Ready worker 1d v1.13.5总结
RKE简化了k8s集群创建流程,降低自建门槛,为有自建需求的企业提供了可靠选择。通过本文步骤,可快速构建高可用集群。
参考资料
Announcing RKE, a Lightweight Kubernetes Installer
An Introduction to Rancher Kubernetes Engine (RKE)