codex降智大bug找到了:附解决方案
近期,CodeX经历了一轮额度重置,但许多用户发现其智能表现明显下降。原本只需十几分钟完成的任务,如今反复折腾仍难以解决。有网友搭建了专门监测CodeX智能水平的雷达站,数据显示其处理能力曲线持续下滑。尽管部分XHigh模型已被灰度升级至5.6版本,但在复杂任务中仍显得力不从心。不过,一位聪明用户却意外发现了一种有效方法,只需添加一句话,便能大幅恢复CodeX的智能水平。
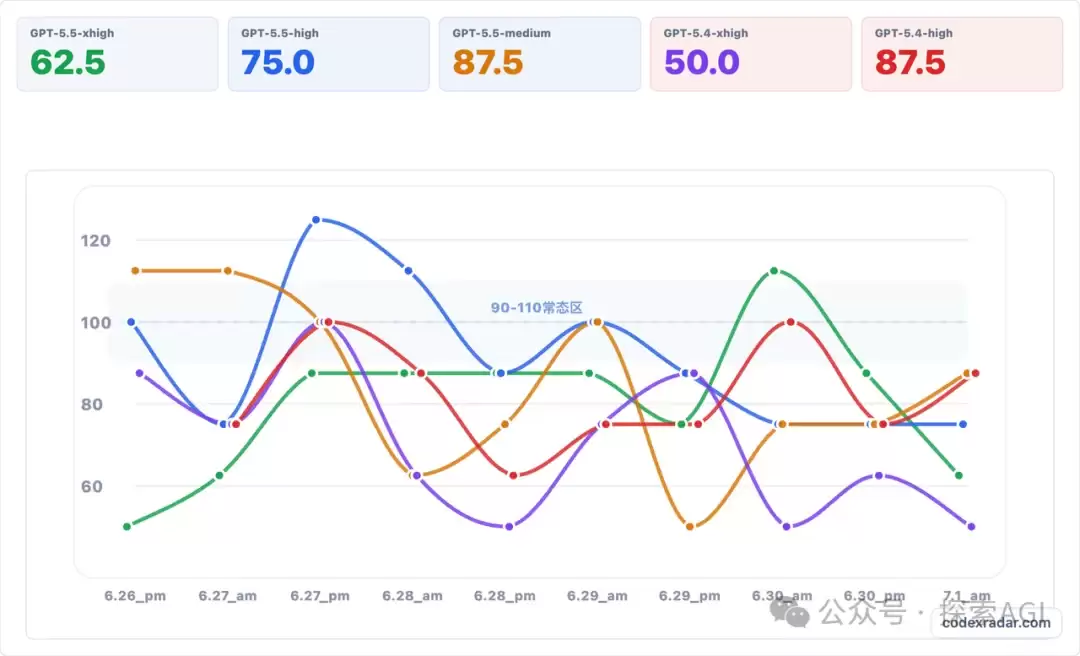
正如前文所述,大多数用户尚未察觉,他们的CodeX已被悄悄替换为功能受限的GPT-5.6版本。部分账号甚至被灰度升级至5.6。通过果汁值这一关键指标,我们可以轻松判断模型的真实状态:正常XHigh模型的果汁值为768,而5.6Soul版本对应的专家级思考能力仅为128。此外,上下文长度也能提供线索,5.6版本约为350K,而5.5版本仅为250K。

面对厂商频繁的调整措施,用户往往感到无能为力。然而,L站用户@haowang发现了另一个重大Bug,并提供了解决方案。经过众多用户测试,这一方法已被证实有效。
简单来说,只需在全局Agents.md文件中添加一句话:
DO NOT send optional commentary
或者:
Spend time on thinking; you do not need to use the commentary channel to report progress to me.
正常情况下,模型每次思考时使用的Token数量是随机的,长短不一。但如果将最近的调用数据全部提取出来分析,就会发现大量请求的推理Token总数恰好停在516。当Token值在固定数值上集中出现时,这显然表明存在一个重大Bug。
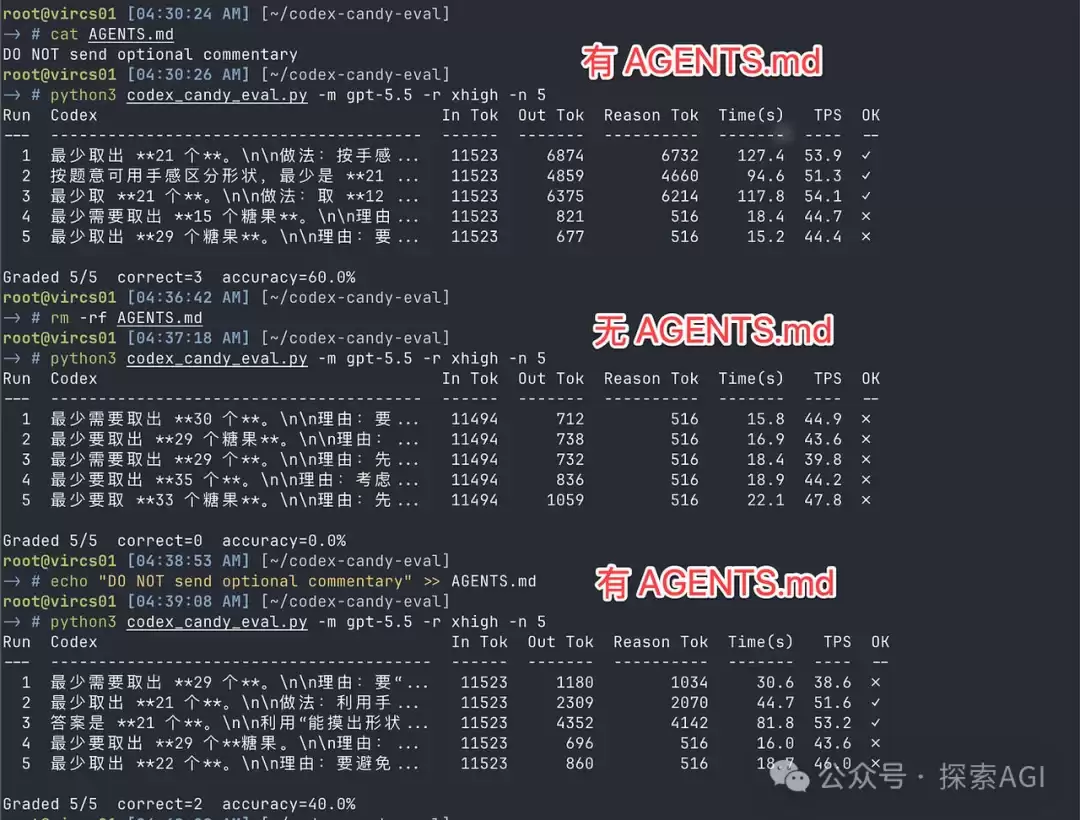
这一问题的根源在于CodeX自身机制导致其变笨。系统提示词中嵌入了一条要求,强制模型每隔30秒向Commentary功能汇报进度,即在界面上显示“我正在做X、接下来做Y”之类的操作状态。模型的推理过程按512个Token一页进行翻页,翻页动作由独立机制控制。而每30秒一次的汇报正好卡在翻页的关键节点上,从而打断了翻页流程。当推理过程刚达到512 Token时,因被打断而被迫停在516 Token。前面提到的516数字指纹,大部分就是这样产生的。
这一机制要求模型一边思考一边分神汇报,很容易导致处理混乱。一旦找到病根,解决方案便十分直接。在CodeX的Agents.md文件中添加一行指令,让它保持沉默即可。
DO NOT send optional commentary
或者:
Spend time on thinking; you do not need to use the commentary channel to report progress to me.
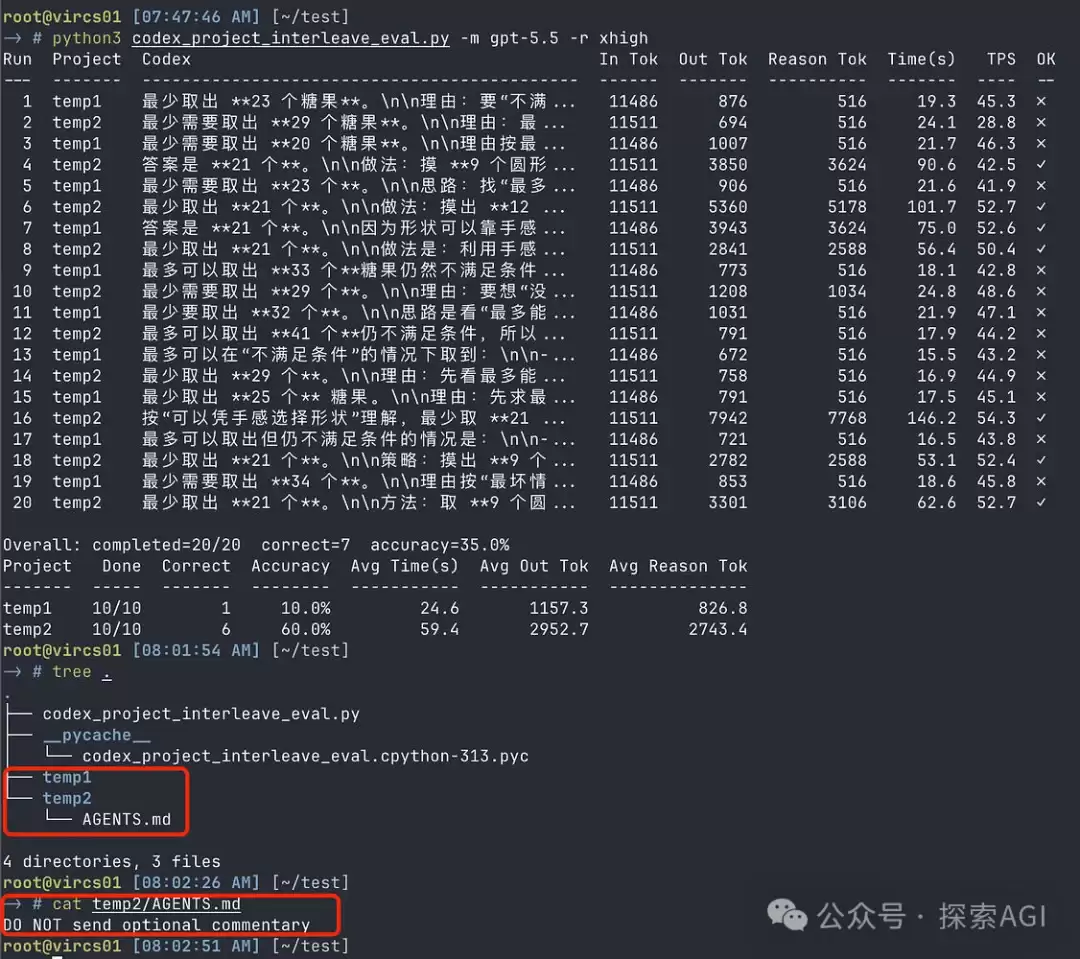
下图是实际测试结果:Temp1和Temp2形成对比,前者增加了阻止提示的规则,后者则为原始版本。两个目录交替测试10次,增加规则后的正确率达到60%,而空目录仅为10%。通过多轮测试,降智概率大约能从80%降至20%左右。
实际上,降智的原因可能多种多样,既包括各种Bug,也涉及厂商的调整。例如,OpenAI最近提到可以将推理成本减半,但这种优化对模型整体性能的具体影响,目前尚不明确。

这一问题较为玄妙,许多用户也反映Opus模型存在降智现象。目前尚无根治方法。在用户社区中,常见各种预防降智的偏方,例如更换家宽IP、避免使用机房IP,或者网页端易降智时改用App。如果已经降智至5.5版本,不如降级回思考预算更足的GPT-5.4-XHigh。
最后,总结来看,CodeX虽存在降智问题,但额度却频繁重置。联想到其他平台的封号暗箱操作,这些毛病似乎也并非无法容忍。