标准本体论 对决 Palantir Ontology
本文旨在剖析W3C标准本体论与Palantir私有本体论之间的本质区别,帮助准确理解数据建模的核心逻辑。核心内容涵盖哲学起源、W3C定义、技术栈构成以及与Palantir建模体系的关键差异对比。
引言
近年来,本体论成为热门话题。在日常技术交流中,“Ontology(本体论)”这一术语主要指向两套截然不同的建模体系:一套是遵循W3C语义网标准定义的信息科学本体论,具备全球统一的开放规范;另一套则是Palantir Foundry平台自主研发的私有建模层,仅在其产品体系内部生效。两者虽然使用同一词汇,但其底层假设、标准规范、核心目标与能力边界存在本质差异。
本文基于W3C官方规范、Palantir官方平台文档以及本体论学术共识,结合个人理解,对这两套体系进行对比分析。
一、本体论的两层本源定义:哲学根基与W3C标准化规范
1. 哲学层面本体论(Ontology词源本源)
本体论起源于哲学中的存在论,其核心研究两大命题:客观世界中存在哪些实体,以及存在物的底层结构与内在关联。代表理论包括亚里士多德的实体-属性二元模型和海德格尔的存在阐释。该体系的底层逻辑是开放的、无预设、且不固化于任何业务流程,仅用于抽象认知世界。它是所有“本体”概念的词源基础,并不直接等同于工程建模工具。
2. 信息科学标准本体论(学界+W3C公认权威定义)
1993年,Gruber提出了基础概念;1997年,Studer、Benjamins和Fensel共同形成了计算机领域的通用完整定义:本体论是对共享概念体系做出明确、形式化的规范说明。该定义包含四大不可拆分的约束,划定了标准本体的核心工程边界。

3. W3C语义网完整配套技术栈
标准本体并非仅能描述静态实体关系。W3C配套了完整的规范,覆盖校验、服务、审计、权限和数据写入等功能,但遵循分层解耦的设计原则,各规范各司其职、互不耦合:
1)RDF/RDFS:作为三元组基础知识描述框架,用于定义类和基础属性。
2)OWL 2:用于扩展子类、等价类、互斥类、基数、传递关系等逻辑公理,支撑全局知识推理。其底层默认采用开放世界假设(OWA),即无明确声明的事实被视为未知,而非虚假。
3)SHACL(形状约束语言):面向RDF实例数据进行校验,采用封闭世界假设,支持字段格式、基数及跨实体业务校验。它仅输出校验报告,不具备事务写入能力。
4)SWRL:基于OWL 2的Horn推理规则,仅能推导新知识事实,无法驱动外部系统变更或事务写入。此外,大量推理机对复杂SWRL的支持有限。
5)OWL-S:作为标准化Web服务语义描述,仅定义接口入参、输出、前置和后置条件,无内置执行引擎、权限控制或审计日志。
6)PROV-O:作为溯源本体标准,仅规范操作记录的语义结构,不提供不可篡改的事务级审计。
7)WebAC:作为RDF资源细粒度访问权限标准,属于上层附加规范,主流本体编辑器和推理引擎并无原生集成。
8)SPARQL Update:作为标准RDF事务写入语法,仅提供数据变更接口。权限、流程和校验等功能需要外部系统独立实现。
关键结论:标准本体具备规则、校验和服务建模能力,但缺乏一体化的执行闭环。业务变更、权限和审计均为外置组件,本体的核心职责聚焦于跨主体知识共享与逻辑推理。其主流落地载体包括RDF图数据库、通用知识图谱和跨机构语义融合项目。
二、Palantir Ontology:平台私有操作语义层
Palantir复用了“Ontology”这一词汇来命名其自研建模框架。该框架不提供原生的OWL/RDF标准格式导出能力,不属于语义网体系下的标准本体实现。
官方核心定位:这是一个面向企业内部决策闭环的一体化语义与运行契约层。它完整整合了数据、业务逻辑、可执行操作及全链路安全治理四大维度,其底层设计目标是为平台内的可控数据双向读写和AI Agent自动化运营提供支持。
五大核心组件与标准本体的对标:
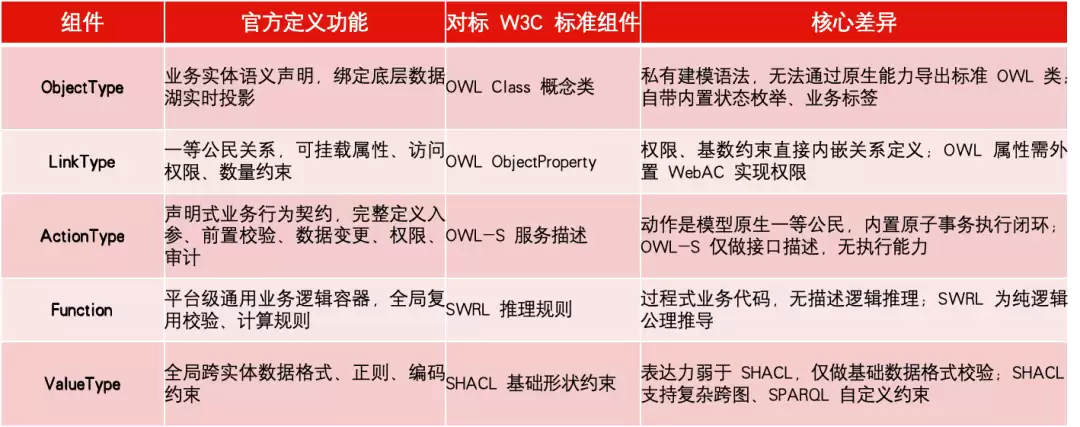
底层存储架构客观说明:
1)原始落地层:业务原始数据持久化于Iceberg、Parquet等列存数据湖中,长期归档采用列式存储。
2)查询计算层:平台内置定制化的属性图索引服务,用于实体关联遍历,这属于内存或计算层的逻辑视图。
3)关键区分:Palantir不独立部署持久的原生图数据库来存储全量实体关系。而主流RDF引擎可以选择图数据库、关系库或数据湖等任意存储载体,二者仅在存储选型思路上存在差异,并无优劣之分。
底层世界观假设核心差异:
1)W3C OWL标准本体:采用开放世界假设(OWA),适用于互联网分布式、信息不完整的场景。
2)Palantir Ontology:采用封闭世界假设(CWA),面向企业内部完整可控的业务数据。未声明的事实直接判定为不成立,适用于确定性的业务流程校验。
三、标准本体论与Palantir Ontology多维度对比
核心公式区分
标准本体论(核心:知识共享与推理)= 领域概念模型 + 关系模型 + 描述逻辑公理模型 + 分层配套标准组件(规则/服务/审计/权限,独立分层)
Palantir Ontology(核心:平台内业务执行)= 业务对象模型 + 链接关系模型 + 内置操作执行模型 + 内嵌运行约束 + 原生三维权限与事务审计模型
对比表:
对比维度 | 标准本体论(OWL/RDF/W3C语义网) | Palantir Ontology |
本质定位 | 跨组织通用的标准化领域知识交换规范 | 单一平台内部私有的业务运行闭环建模框架 |
核心目标 | 统一跨系统语义、实现异构数据互通、进行自动化逻辑蕴含推理 | 统一平台内业务执行、支持双向数据回写、实现全流程合规审计、进行AI受控操作 |
核心组成主次 | 以概念、关系和逻辑公理为主;动作/权限/审计为分层配套标准组件 | 以对象、链接和Action行为为核心;权限、校验和审计深度耦合在模型定义中 |
业务动作建模能力 | 可通过OWL-S建模服务接口,但仅提供契约描述,无原生执行引擎 | ActionType是原生一等公民,内置完整的事务执行链路 |
数据写回闭环 | SPARQL Update提供写入接口,但事务、校验和审计需外部系统拼接实现 | Action内置原子事务:参数校验→权限校验→前置规则→数据写入→同步生成不可篡改审计日志→外部系统同步,形成一体化闭环 |
权限体系实现 | WebAC国际标准,独立于本体模型,跨系统通用;但主流工具无原生集成 | 对象/字段/Action三级内嵌权限,基于角色、数据标记和使用目的进行三维管控,平台原生生效 |
审计溯源特性 | PROV-O仅定义溯源语义,无事务级不可篡改日志绑定 | 写入操作与审计日志在同一事务中持久化,日志采用私有格式,仅平台内可解析 |
核心执行引擎 | DL描述逻辑推理引擎:支持完备、可靠且可判定的自动化逻辑推理,可自动推导子类、传递关系和等价实体等隐含知识 | 业务执行引擎:驱动Action完成数据变更;无通用描述逻辑推理能力,仅支持自定义的过程式代码判断 |
底层存储适配 | 无明确绑定,兼容图数据库、关系库、数据湖及文件系统等任意载体 | 原生适配Iceberg/Parquet数据湖,脱离Palantir平台后无法直接迁移模型 |
形式化逻辑强度 | 极高,基于可判定的OWL 2描述逻辑,支持完备、可靠且可判定的全局知识推理 | 中等,仅采用业务声明式契约语法,无公理推理体系,仅在运行时进行逐条校验 |
适用使用者 | 知识工程师、跨机构协同项目、多系统数据融合、知识检索RAG场景 | 企业内部运营团队、平台内AI Agent、业务合规决策者、内部一体化运营项目 |
AI协作模式 | 为跨数据源的RAG提供标准化语义索引;LLM需对接外部API和权限系统完成操作,无原生人工复核流程 | 为平台Agent提供完整的Action契约;运行时根据角色和实体状态动态过滤可用操作;原生提供Proposal提案机制,AI仅生成变更草案,人工审核后执行 |
标准化互通性 | 遵循W3C开放国际标准,模型可导出为RDF/OWL/SHACL,无厂商锁定风险 | 完全私有封闭规范,无原生标准语义导出能力,存在强厂商锁定,模型无法原生跨平台复用 |
工程落地成本 | 轻量本体可快速搭建;但复杂业务执行场景需额外集成流程、权限和审计组件,集成成本较高 | 一站式集成语义、执行和安全能力;但建模门槛高,Schema刚性较强,业务迭代修改模型成本较高 |
案例对照:车辆生产领域建模
1. W3C标准本体完整建模
a)使用OWL 2定义概念类:车辆Vehicle、零件Part;定义对象属性:Vehicle requires Part。
b)使用OWL 2定义公理:车辆生产必须配套全部必需零件。
c)使用SHACL定义约束:零件库存数值不可为负数。
d)使用SWRL定义规则:若零件库存小于需求数量,则推导出“禁止生产”的事实。
e)使用OWL-S定义标准化的“启动生产”服务接口,明确入参和访问权限。
f)使用PROV-O定义操作溯源记录的语义。
短板:整套模型仅能进行推导、校验和接口描述,无法原生驱动MES/ERP系统进行同步写入,缺少内置的事务、审计和权限拦截逻辑,需要额外开发外部执行层。
2. Palantir Ontology建模
a)定义ObjectType:车辆Vehicle,内置生产状态枚举(如计划中、生产中、已完工)。
b)定义LinkType:车辆-需要零件,链接上挂载需求量、必需标记和访问权限。
c)定义ActionType:startProduction启动生产,内置六层原子执行链路:参数格式校验→角色与数据标记权限校验→Function校验零件库存前置条件→原子事务更新车辆状态→同步生成不可篡改审计日志→自动双向同步数据至MES/ERP外部系统。
二者均可覆盖实体描述与生产流程管控。核心架构差异在于:标准本体依靠多套开放标准分层拼接实现,具备跨平台复用性,但缺少执行闭环;Palantir则将全部执行与管控能力耦合进建模语法,平台内一站式可用,但无法对外互通。
四、建模分层体系说明
行业技术社区中存在一种三层建模分层的表述方式。该分层在技术社区讨论中常见,但并无W3C、ISO或学术界的通用权威标准作为支撑,仅作为辅助理解的能力分层视角,不代表层级之间存在代际优劣或高低之分。
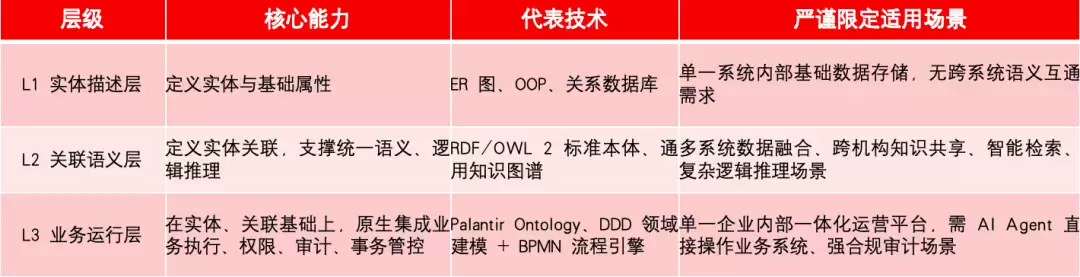
补充说明:L3并非Palantir独有的范式,DDD聚合根、BPMN流程引擎等均属于同类用于“描述业务如何运行”的成熟方案。Palantir的差异化之处在于将执行和安全逻辑深度嵌入到语义建模层中。
五、大模型AI时代:两套体系差异化价值
二者精准定位区分
标准W3C本体论旨在解决AI跨平台读懂知识、互通数据以及进行全局逻辑推理的需求。
Palantir Ontology旨在解决单一企业内部AI安全、合规以及一体化执行业务操作的需求。
二者能力互补,不存在互相替代的关系。工程实践中可以采用混合架构进行落地,例如,内部采用Palantir进行运营建模,上层则采用OWL 2标准本体实现对外跨组织的数据互通。
1. 标准W3C本体论+LLM
优势
a)标准化的语义结构,能够支撑跨数据源和跨机构的RAG知识检索,统一异构知识库的语义。
b)采用开放格式,LLM可以对接所有兼容W3C标准的外部系统,不存在平台绑定问题。
c)具备完备的DL逻辑推理能力,可以依靠本体公理约束大模型输出,有效降低知识幻觉。
客观局限
a)执行链路较为分散,LLM在调用业务操作时需要额外对接API、权限和审计模块,整体集成成本更高。
b)缺少原生的提案审批闭环。虽然可以基于外部工作流搭建人工复核流程,但这并非本体原生的内置能力。
2. Palantir Ontology+LLM/AI Agent
优势
a)Agent可以统一识别平台内的语义对象,无需适配多套异构业务接口。
b)Action自带完整契约,包括入参规范、权限拦截、前置业务规则、原子事务和审计日志,形成一体化能力。
c)运行时可以根据用户角色和实体的实时状态动态裁剪Agent可执行的Action列表,实现精细化的权限隔离。
d)原生支持Proposal提案机制:AI仅生成变更提案,由人工审核确认后执行,大幅降低了误操作风险。
客观局限
a)本体模型、Action定义和权限规则完全私有封闭,Agent能力无法跨平台原生复用,仅适用于Palantir体系内部。
b)缺失通用描述逻辑推理能力,在复杂多维度知识推导和跨实体蕴含计算方面弱于OWL 2标准本体。
c)存在平台重度绑定问题,整套模型和业务规则无法原生迁移至其他数据平台,长期存在厂商锁定风险,建模与维护成本偏高。
六、总结:两套体系取舍逻辑与选型客观结论
W3C标准本体论如同全球通用的标准化地图,其优势在于统一的语义语言、跨组织自由互通、无平台绑定以及强大的全局逻辑推理能力。其短板在于仅提供静态知识描述框架,若要落地业务变更和流程管控,需要额外集成流程、权限和审计等外部组件,构建一站式运营闭环的成本较高。
Palantir Ontology则如同企业专属的一体化操作系统,其优势在于企业内部可在一套体系内完成语义查看、业务调度、权限管控、操作留痕和双向数据变更,AI Agent可直接安全地执行业务。其短板在于仅适配自有平台,更换数据系统需要完整重构整套模型;Schema刚性较强,在快速迭代多变业务时改造成本高,且存在厂商锁定风险。
综上所述,虽然两者共用“本体”这一词汇,但存在本质区别。技术选型需要结合短期业务落地和长期数据互通的诉求进行综合判断,不应简单判定某一套体系全面优于另一套。