1600万视频解锁“空间智能”?智源3D生成模型See3D全套开源
See3D模型实现了从视频生成可控3D场景的创新突破,通过基于无标注互联网视频的创新方法,为3D内容创作开辟了新路径。

近期,由智源研究院推出的See3D模型,在学习了海量无标注视频数据后,展现出重建全新3D世界的能力,其效果令人惊叹。在此之前,斯坦福大学教授李飞飞团队已推出首个空间智能模型,仅凭单张图片即可生成逼真3D场景,被视为空间智能领域的重要突破。
与之并行推进的是,智源研究院发布了首个基于大规模无标注互联网视频学习的3D生成模型See3D,其理念为“观看视频,获取3D”。这一模型与传统依赖相机参数的方式不同,采用了视觉条件技术,仅借助视频中的视觉线索,就能生成相机方向可控且几何一致的多视角图像。该方法不依赖昂贵的3D或相机标注,可以从多样化的互联网视频中高效学习3D先验知识。
See3D不仅支持零样本和开放世界的3D生成,还能在不进行微调的情况下执行3D编辑和表面重建等任务,在多种3D创作应用中展现出广泛适用性。

See3D能够支持从文本、单视图和稀疏视图生成3D,同时兼容3D编辑与高斯渲染功能。相关模型、代码和Demo已全部开源,更多技术细节可参考See3D论文。
论文地址:https://arxiv.org/abs/2412.06699
项目地址:https://vision.baai.ac.cn/see3d
效果展示
1. 解锁3D互动世界:输入图片后,可生成沉浸式可交互3D场景,实时探索真实空间结构。为实现实时交互式渲染,当前对3D模型和渲染过程进行了简化,离线渲染下的真实效果更佳。
2. 基于稀疏图片的3D重建:输入稀疏的3至6张图片,模型能够生成精细化的3D场景。例如,基于6张视图的3D重建和基于3张视图的3D重建都能获得高质量结果。
3. 开放世界3D生成:根据文本提示生成艺术化图片,并基于此图片生成虚拟化3D场景。
4. 基于单视图的3D生成:输入一张真实场景图片,模型可生成逼真的3D场景。
研究动机
3D数据具有完整的几何结构和相机信息,能提供丰富的多视角信息,是训练3D模型的最直接选择。然而,现有方法通常依赖人工设计、立体匹配或运动恢复结构等技术来收集数据。尽管经过多年发展,当前3D数据的积累规模依然有限,例如DLV3D(0.01M)、RealEstate10K(0.08M)、MVImgNet(0.22M)和Objaverse(0.8M)。这些数据的采集过程不仅耗时且成本高昂,难以扩展,无法满足大规模应用需求。
与之不同,人类视觉系统无需依赖特定3D表征,仅通过连续多视角观察即可建立对三维世界的理解。单帧图像难以实现这一点,而视频因其天然包含多视角关联性和相机运动信息,具备揭示3D结构的潜力。更重要的是,视频来源广泛且易于获取,具有高度可扩展性。基于此,See3D提出“看视频,得3D”的理念,旨在通过视频中的多视图信息,让模型像人类一样学习并推理物理世界的三维结构,而非直接建模其几何形态。
方法介绍
为实现可扩展的3D生成,See3D提供了一套系统化解决方案,具体包括:
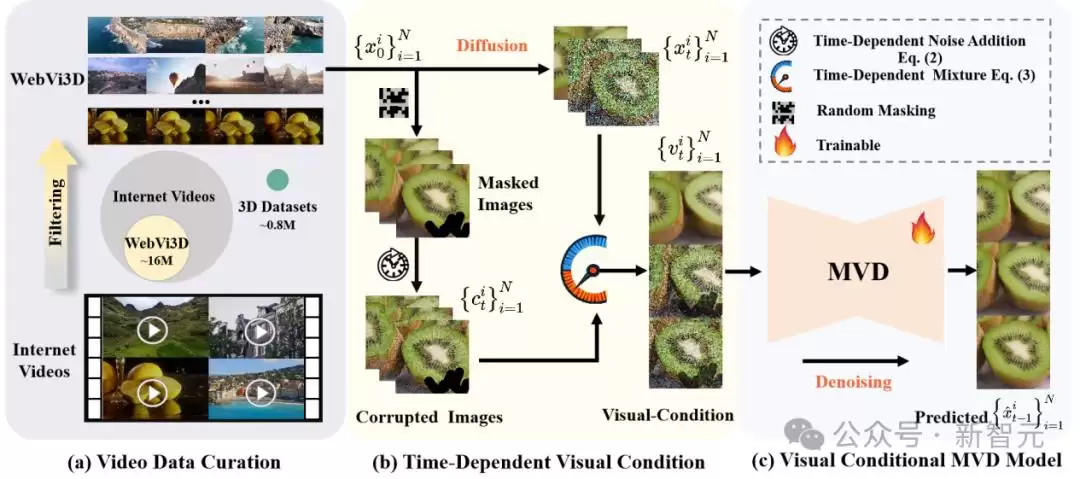
1. 数据集:团队提出了一个视频数据筛选流程,自动去除源视频中多视角不一致或观察视角不充分的片段,构建了高质量、多样化的大规模多视角图像数据集WebVi3D。该数据集涵盖来自1600万个视频片段的3.2亿帧图像,可通过自动化流程随互联网视频量的增长而不断扩充。
2. 模型:标注大规模视频数据的相机信息成本极高,在缺乏显式3D几何或相机标注的情况下,从视频中学习通用3D先验是更具挑战的任务。为解决这一问题,See3D引入了一种新的视觉条件——通过向掩码视频数据添加时间依赖噪声,生成纯粹的2D归纳视觉信号。这一视觉信号支持可扩展的多视图扩散模型训练,避免了对相机条件的依赖,实现了“仅通过视觉获得3D”的目标,绕过了昂贵的3D标注。
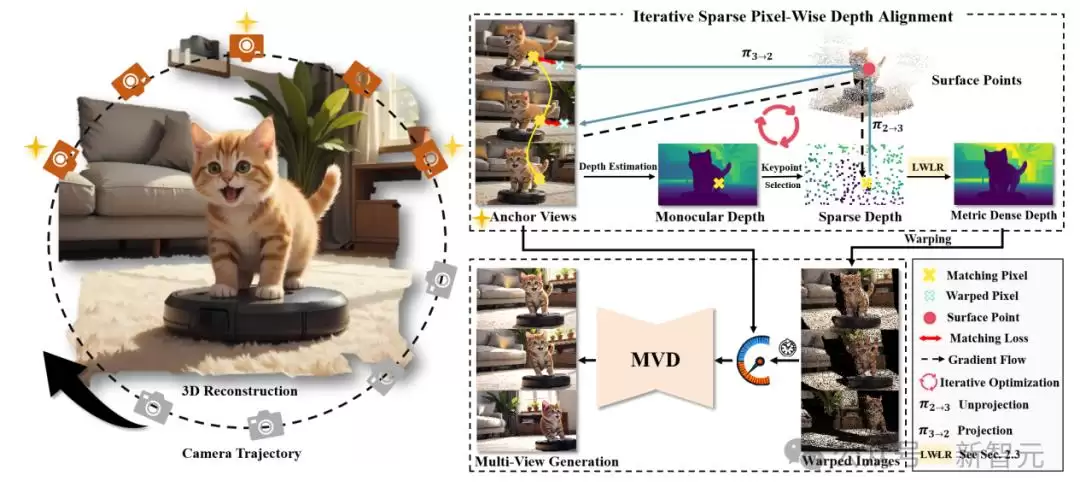
3. 3D生成框架:See3D所学习的3D先验能够使一系列3D创作应用成为可能,包括基于单视图的3D生成、稀疏视图重建以及开放世界场景中的3D编辑等,支持在物体级与场景级复杂相机轨迹下的长序列视图生成。
优势
1. 数据扩展性:模型的训练数据源自海量互联网视频,相较于传统3D数据集,构建的多视图数据集在规模上实现了数量级提升。随着互联网的持续发展,该数据集可持续扩充,进一步增强模型能力的覆盖范围。
2. 相机可控性:模型支持在任意复杂相机轨迹下生成场景,既能实现场景级别的漫游,也能聚焦于场景内特定的物体细节,提供灵活多样的视角操控能力。
3. 几何一致性:模型支持长序列新视角的生成,保持前后帧视图的几何一致性,并遵循真实三维几何的物理规则。即使视角轨迹发生变化,返回时场景依然保持高度逼真和一致性。
总结
通过扩大数据集规模,See3D为突破3D生成的技术瓶颈提供了全新思路,其学习到的3D先验知识为一系列3D创作应用奠定了坚实基础。这项工作有望引发3D研究社区对大规模无相机标注数据的关注,降低高昂的3D数据采集成本,同时缩小与现有强大闭源3D解决方案之间的差距。