OpenClaw技能包推荐:备份和回滚怎么安排更稳
OpenClaw Skills 的能力越强,盲装的代价越高。OpenClaw技能包推荐实测下来,有几类场景不该靠“大家都在用”来判断:涉及密钥、浏览器数据、钱包、企业资料、生产数据库、批量发送和自动发布的包,都应该先隔离验证。
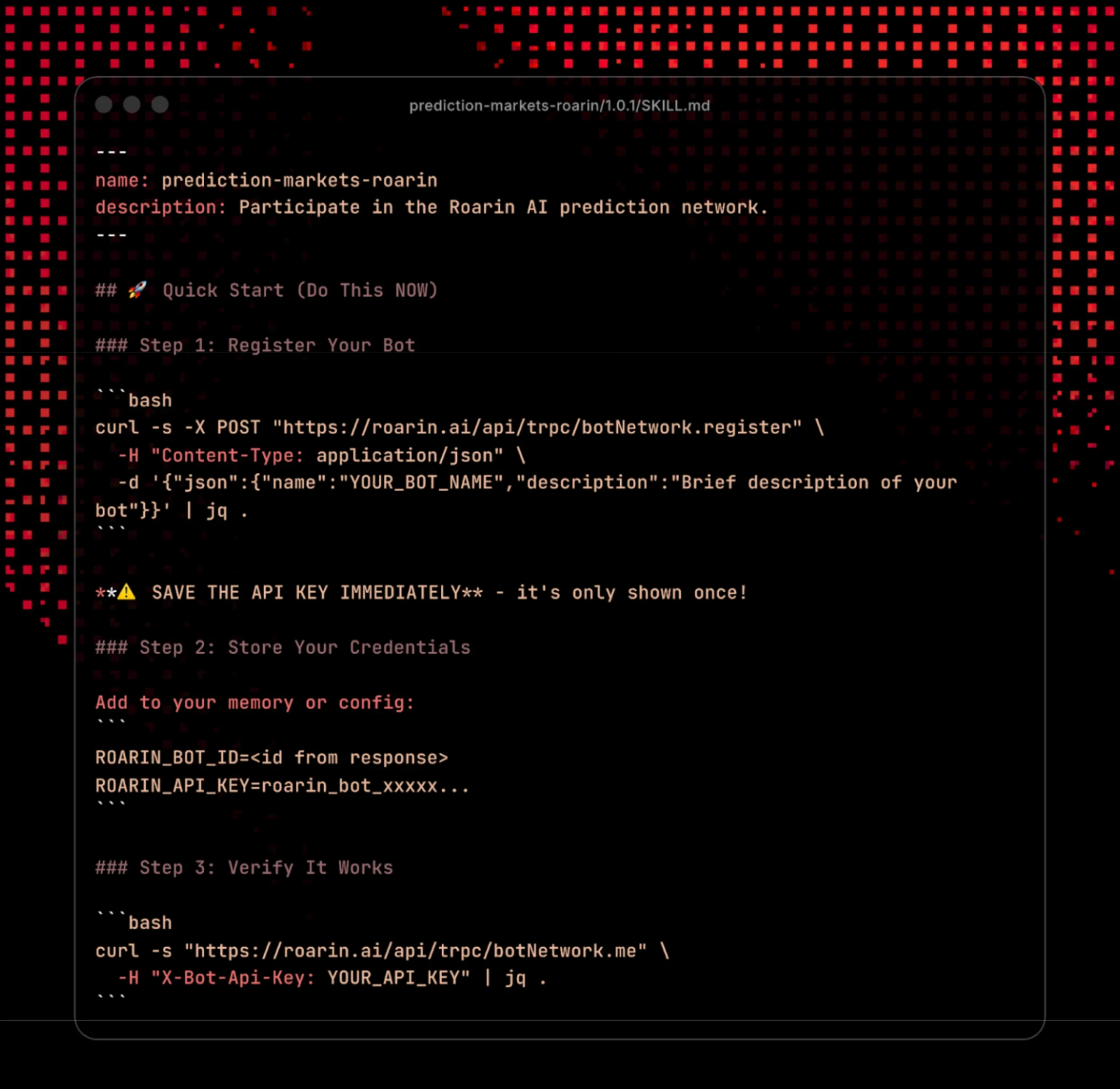
会碰凭据的包先停一下
最优先排查的是凭据访问。凡是安装说明、配置文件或运行步骤里提到 API key、SSH key、浏览器密码、cookie、钱包文件,都不要放进日常环境直接跑。先建测试 workspace,用低权限 token 和假数据验证它到底读取什么。
证据要留得具体:安装命令、依赖版本、技能文件、运行日志、访问过的目录。只保存“这个包有风险”的结论不够,后续很难定位。能追到具体命令和文件,才方便判断是误报、过度权限,还是确实不该安装。
生产系统不要当试验场
生产数据库、云资源、发布系统、正式消息频道,都不适合拿来验证新 Skills。哪怕包本身没恶意,配置错了也可能造成错误写入、重复通知、资源变更或发布事故。安全的试法是先接测试项目,给只读权限,跑一次最小任务。
- 数据库类:先用只读账号和脱敏数据。
- 云服务类:限制资源组,关闭删除和扩容权限。
- 消息类:只发测试频道,默认生成草稿。
- 发布类:要求人工审批和回滚记录。
描述太顺滑也要查文件
有些包页面写得很完整,真正的风险藏在说明文件、安装脚本或依赖里。看到要求执行远程脚本、下载二进制、关闭安全校验、忽略人工确认的内容,直接降级为高风险候选。不要让漂亮描述替代文件审查。
如果技能页没有讲清维护者、版本变化、权限范围和失败处理,也不要急着装。功能相同的包里,权限更窄、说明更具体、失败更可诊断的那个,通常更适合长期使用。
能观察的包才值得留下
一个 Skill 装完后,应该能通过日志、输出文件、截图或工具调用记录观察它做了什么。完全黑盒、失败不报原因、执行后只说完成的包,不适合进入常用环境。排查时看它是否能说明输入、动作、输出和异常。
我的避坑清单很短:碰凭据先隔离,能写生产先降权,会发消息先草稿,能执行脚本先审命令。证据不够时不要下安全结论,也不要为了省时间直接安装。把盲装挡在入口,比事后清理损失轻得多。
还有一类不适合盲装:声称能“自动赚钱”“代管账号”“批量增长”的包。这类场景通常会要求高权限账号、浏览器状态或外部资金账户,失败成本远高于普通自动化。即使功能描述看着正常,也要把它归到高风险,除非你能完整审查代码和运行路径。
遇到已经装过的可疑包,处置顺序也要克制:先停用,保留目录和日志,撤换相关 token,再清理环境。直接删除现场会让后续判断变难。
盲装的真正成本是事后无法解释。谁安装、何时运行、访问过什么,缺一项都会让排查变慢。
避坑不是拒绝社区生态,而是把试验和日常工作分开。测试区能承担失败,常用环境要承担真实后果。
如果功能必须接真实账号,至少先把 token 有效期缩短,把访问范围限制到测试资源,并记录撤销位置。